Harnessing NLP for Polymer Data Extraction: Transforming Materials Science and Biomedical Research
This article explores the transformative potential of Natural Language Processing (NLP) in automating the extraction of polymer data from scientific literature, addressing a critical bottleneck in materials informatics.
Harnessing NLP for Polymer Data Extraction: Transforming Materials Science and Biomedical Research
Abstract
This article explores the transformative potential of Natural Language Processing (NLP) in automating the extraction of polymer data from scientific literature, addressing a critical bottleneck in materials informatics. We examine the foundational challenges of data scarcity in polymer science and present advanced NLP methodologies, including domain-specific language models like MaterialsBERT, which has been used to extract over 300,000 property records from 130,000 abstracts. The content provides a comprehensive analysis of troubleshooting common implementation hurdles, such as data quality and model interpretability, and offers validation frameworks for assessing extraction accuracy. Designed for researchers, scientists, and drug development professionals, this guide synthesizes technical insights with practical applications, highlighting how NLP-driven data pipelines can accelerate discovery in biomedical and clinical research by unlocking chemistry-structure-property relationships from vast text corpora.
The Polymer Data Challenge: Why NLP is Revolutionizing Materials Discovery
The Growing Data Crisis in Polymer Science
The field of polymer science is experiencing a rapid acceleration in data generation, yet a substantial amount of historical and newly published data remains trapped in unstructured formats within scientific journal articles [1]. This creates a critical bottleneck for modern materials informatics, which relies on the availability of structured, machine-readable datasets to advance discovery [1] [2]. The core of the data crisis lies in the fact that while computational and experimental workflows systematically generate new data, an immense body of knowledge is locked in published literature as unstructured prose, impeding immediate reuse by data-driven methods [2]. One study highlights the magnitude of this problem, noting that a corpus of approximately 2.4 million materials science journal articles yielded 681,000 polymer-related documents containing over 23 million paragraphs, from which automated extraction pipelines successfully identified over one million property records for just 24 targeted properties [1]. This demonstrates both the vast potential and the significant challenge of liberating trapped polymer data.
NLP and LLM-Driven Solutions for Data Liberation
Foundational Technologies
The application of Natural Language Processing (NLP) and Large Language Models (LLMs) to polymer science literature seeks to automatically extract materials insights, properties, and synthesis data from text [1]. Foundational to this process is Named Entity Recognition (NER), which identifies key entities such as materials, characterization methods, or properties [1]. Transformer-based architectures like BERT have demonstrated superior performance in this domain, leading to the development of domain-specific models such as MaterialsBERT, which is derived from PubMedBERT and fine-tuned for materials science tasks [1].
More recently, general-purpose LLMs like GPT, LlaMa, and Gemini have shown remarkable robustness in handling various NLP tasks, including high-performance text classification, NER, and extractive question-answering, even with limited datasets [1] [2]. Their key advantage lies in the semi-supervised pre-training on vast scientific corpora, which grants them a foundational comprehension of language semantics and contextual understanding, enabling them to perform in-domain tasks with no (zero-shot) or only a few task-specific examples (few-shots) [1].
Comparative Performance of Extraction Models
Table 1: Comparison of model performance and costs for polymer data extraction.
| Model | Primary Strength | Reported Performance / Accuracy | Key Limitation / Cost Factor |
|---|---|---|---|
| MaterialsBERT [1] | Effective for NER; superior on materials-specific datasets. | Successfully extracted >300,000 records from ~130,000 abstracts. | Struggles with complex entity relationships across long text spans. |
| GPT-3.5 & GPT-4.1 [1] [2] | High extraction accuracy and versatility. | F1 ~0.91 for thermoelectric properties; used to extract >1 million polymer records [2]. | High computational cost and API fees [1]. |
| GPT-4.1 Mini [2] | Balanced performance and cost. | Nearly comparable to larger GPT models. | Slightly reduced accuracy. |
| Llama-2-7B-Chat [1] [3] | Open-source; enables fine-tuning for specific tasks. | Achieved 91.1% accuracy for injection molding parameters with fine-tuning [3]. | Requires fine-tuning for optimal performance; computational overhead for training. |
Application Notes & Protocols: An LLM-Driven Extraction Pipeline
This protocol details an automated pipeline for extracting polymer property data from scientific literature, leveraging a hybrid approach of heuristic filtering, NER, and LLMs to optimize for both accuracy and computational cost [1].
Data Acquisition and Preprocessing
- Corpus Assembly: Begin by assembling a corpus of full-text journal articles from authorized publisher portals (e.g., Elsevier, Wiley, Springer Nature, American Chemical Society, Royal Society of Chemistry) using Crossref indexing and APIs for bulk downloading [1] [2].
- Polymer Document Identification: Identify polymer-related documents within the corpus by searching for key terms (e.g., "poly") in article titles and abstracts. This filtering can reduce a multi-million article corpus to a focused subset of several hundred thousand documents for processing [1].
- Text Unit Segmentation: Treat individual paragraphs as the fundamental text units for processing. This granular approach helps isolate discrete pieces of information [1].
- Text Cleaning (Optional but Recommended): For more complex workflows, preprocess the full text by removing non-relevant sections such as "Conclusion" and "References" which typically do not contain property information. Use rule-based scripts with regular expressions to retain only sentences likely to contain target properties, thereby increasing token efficiency for subsequent LLM processing [2].
Two-Stage Paragraph Filtering
To avoid unnecessary and costly LLM prompts, a two-stage filtering mechanism is employed to identify paragraphs with a high probability of containing extractable data [1].
- Stage 1: Heuristic Filter: Pass each paragraph through property-specific heuristic filters. These filters use manually curated lists of target polymer properties and their co-referents (e.g., "Tg" for "glass transition temperature") to detect relevant paragraphs. Only a fraction of paragraphs (e.g., ~11%) are expected to pass this initial filter [1].
- Stage 2: NER Filter: Apply a NER model (e.g., MaterialsBERT) to the remaining paragraphs to confirm the presence of all necessary named entities:
material name,property name,numerical value, andunit. The absence of any of these entities indicates an incomplete record. This stage further refines the dataset to the most promising paragraphs (e.g., ~3% of the original total) [1].
Information Extraction with LLMs
- Model Selection: Choose an LLM based on the trade-off between required accuracy and available budget (refer to Table 1). For high-throughput, cost-sensitive applications, GPT-4.1 Mini or a finely-tuned open-source model like Llama 2 may be optimal [2].
- Prompt Engineering: Design precise prompts for the LLM to perform structured data extraction. Use few-shot learning by providing clear examples of input text and the desired structured output (e.g., in JSON format) within the prompt to guide the model [1]. The prompt should instruct the model to identify the polymer material, the property, its numerical value, and its units.
- Structured Output Parsing: Execute the LLM calls on the filtered paragraphs. The output should be a structured data record (e.g., a JSON object). Implement automated scripts to parse these outputs and aggregate them into a master database [3] [2].
- Multi-Agent Workflows (Advanced): For complex extractions involving multiple data types (e.g., thermoelectric and structural properties), consider an agentic workflow using a framework like LangGraph. This involves specialized agents (e.g., Material Candidate Finder, Property Extractor) working in concert, with dynamic routing and conditional branching for robust, high-quality data extraction [2].
Data Validation and Publication
- Benchmarking: Manually curate a gold-standard test set from a subset of papers. Use this to benchmark the performance (precision, recall, F1-score) of your chosen extraction pipeline [2].
- Data Normalization: Normalize extracted units and material names to a standard nomenclature to ensure consistency across the dataset (e.g., converting "°C" to "C", "MPa" to "GPa") [2].
- Public Dissemination: Make the extracted data publicly available via an interactive web platform or data repository to support broader scientific community efforts [1] [2].
The following workflow diagram illustrates the complete pipeline from data acquisition to publication.
The Scientist's Toolkit: Key Research Reagents & Solutions
Table 2: Essential computational tools and models for polymer data extraction.
| Item / Resource | Function / Description | Application in Pipeline |
|---|---|---|
| MaterialsBERT Model [1] | A domain-specific NER model fine-tuned on materials science text. | Accurately identifies and tags key entities (materials, properties, values) in text during the NER filtering stage. |
| GPT / LlaMa LLMs [1] [3] | General-purpose large language models capable of understanding and generating text. | The core engine for relationship extraction and structuring of data from filtered paragraphs based on prompts. |
| QLoRA Fine-Tuning [3] | An efficient fine-tuning method that reduces computational overhead. | Adapts open-source LLMs (e.g., LlaMa-2) for highly specific tasks like extracting injection molding parameters with minimal data. |
| LangGraph Framework [2] | A library for building stateful, multi-actor applications with LLMs. | Orchestrates complex, multi-agent extraction workflows where different specialized LLM agents handle sub-tasks. |
| WebAIM Contrast Checker [4] | An online tool to verify color contrast ratios against WCAG guidelines. | Ensures that any data visualizations or diagrams created from the extracted data meet accessibility standards. |
| Regular Expression Patterns [1] [2] | Sequences of characters defining a search pattern. | Forms the basis of heuristic filters to initially sift through millions of paragraphs for property-related content. |
The growing data crisis in polymer science, characterized by vast quantities of information remaining locked in unstructured literature, is now being addressed through sophisticated NLP and LLM-driven pipelines. The protocols outlined here provide a roadmap for researchers to systematically liberate this data, transforming it into a structured, accessible format that fuels materials informatics and accelerates the discovery of next-generation polymers.
The overwhelming majority of materials knowledge is published as scientific literature, creating a significant obstacle to large-scale analysis due to its unstructured and highly heterogeneous format [5]. Natural Language Processing (NLP), a domain of artificial intelligence, provides the methodological foundation for transforming this textual data into structured, actionable knowledge by enabling machines to understand, interpret, and generate human language [6] [7]. For materials researchers, NLP technologies offer powerful capabilities to automatically construct large-scale materials datasets from published literature, thereby accelerating materials discovery and data-driven research [8].
The application of NLP to materials science represents a paradigm shift in how researchers extract and utilize information. Where traditional manual literature review is time-consuming and limits the efficiency of large-scale data accumulation, automated information extraction pipelines can process hundreds of thousands of documents in days rather than years [8] [9]. This primer examines the core NLP technologies, presents detailed application protocols for polymer data extraction, and provides practical implementation frameworks tailored specifically for materials researchers.
Core NLP Concepts and Technologies
Fundamental NLP Components
NLP encompasses a range of technical components that work together to transform unstructured text into structured data. For materials science applications, several core concepts are particularly relevant:
- Tokenization: The process of separating strings of text into individual words or phrases (tokens) for further processing [6]
- Named Entity Recognition (NER): Identification and classification of key entities in text, such as material names, properties, values, and synthesis parameters [6] [7]
- Part-of-Speech Tagging: Assignment of grammatical categories (nouns, verbs, adjectives) to tokens to understand syntactic structure [7]
- Relationship Extraction: Classification of relationships between extracted entities, such as associating a property value with a specific material [8]
- Sentiment Analysis: Determination of emotional tone or attitude in text, though in materials science this often adapts to classify statements about material performance or characteristics [6]
Evolution of NLP Approaches
NLP methodologies have evolved through distinct phases, from early rule-based systems to contemporary deep learning approaches:
Rule-based systems initially relied on predefined linguistic rules and patterns to process and analyze text, using handcrafted rules to interpret text features [7]. These systems were limited to narrow domains and required significant expert input.
Statistical methods employed mathematical models to analyze and predict text based on word frequency and distribution, using techniques like Hidden Markov Models for sequence prediction tasks [7].
Machine learning approaches applied algorithms that learn from labeled data to make predictions or classify text based on features, enabling more adaptable systems [7].
Deep learning and transformer architectures now represent the state-of-the-art, with models that automatically learn features from data and capture complex contextual relationships [8] [7]. The transformer architecture, characterized by the attention mechanism, has become the fundamental building block for large language models (LLMs) that demonstrate remarkable capabilities in materials information extraction [8].
NLP Applications in Materials Research
Polymer Data Extraction Applications
NLP techniques have demonstrated particular utility in polymer informatics, where they address critical data scarcity challenges:
Table 1: Representative Polymer Data Extraction Applications
| Application Focus | Scale | Key Results | Reference |
|---|---|---|---|
| General polymer property extraction from abstracts | ~130,000 abstracts | ~300,000 material property records extracted in 60 hours | [9] |
| Full-text polymer property extraction | ~681,000 articles | Over 1 million records for 24 properties across 106,000 unique polymers | [1] |
| Polymer nanocomposite synthesis parameter retrieval | Not specified | Successful extraction of synthesis conditions and parameters | [10] |
| Structured knowledge extraction from PNC literature | Not specified | Framed as NER and relationship extraction task with seq2seq models | [10] |
Materials Discovery and Design
Beyond simple data extraction, NLP enables more sophisticated materials discovery applications. Word embeddings—dense, low-dimensional vector representations of words—allow materials science knowledge to be encoded in ways that capture semantic relationships [8]. These representations enable materials similarity calculations that can assist in new materials discovery by identifying analogies and patterns not immediately apparent through manual literature review [8].
Language models fine-tuned on materials science corpora have been employed for property prediction tasks, including glass transition temperature prediction for polymers [9]. More recently, the emergence of prompt-based approaches with large language models (LLMs) offers a novel pathway to materials information extraction that complements traditional NLP pipelines [8].
Experimental Protocols for Polymer Data Extraction
Protocol 1: NER-Based Pipeline for Polymer Property Extraction
This protocol outlines the methodology for extracting polymer property data using a specialized Named Entity Recognition model, MaterialsBERT, applied to scientific abstracts [9].
Research Reagent Solutions
Table 2: Essential Components for NER-Based Extraction Pipeline
| Component | Function | Implementation Example |
|---|---|---|
| Text Corpus | Source materials literature | 2.4 million materials science abstracts [9] |
| Domain-Specific Language Model | Encodes materials science terminology | MaterialsBERT (trained on 2.4 million abstracts) [9] |
| Annotation Framework | Creates labeled data for model training | Prodigy annotation tool with 750 annotated abstracts [9] |
| Named Entity Recognition Model | Identifies and classifies material entities | BERT-based encoder with linear classification layer [9] |
| Entity Ontology | Defines target entity types | 8 entity types: POLYMER, PROPERTYNAME, PROPERTYVALUE, etc. [9] |
Step-by-Step Methodology
Corpus Collection and Preprocessing
- Assemble a corpus of materials science abstracts (2.4 million abstracts in the reference implementation)
- Filter for polymer-relevant content using keyword searches (e.g., "poly")
- Further filter abstracts containing numeric information likely to represent property values [9]
Annotation and Ontology Development
- Define an entity ontology specific to materials science, including: POLYMER, POLYMERCLASS, PROPERTYNAME, PROPERTYVALUE, MONOMER, ORGANICMATERIAL, INORGANICMATERIAL, MATERIALAMOUNT
- Manually annotate 750 abstracts using the Prodigy annotation tool
- Split annotated data into training (85%), validation (5%), and test sets (10%) [9]
Model Training and Optimization
- Initialize with MaterialsBERT encoder (pre-trained on materials science abstracts)
- Add a linear classification layer with softmax activation for entity type prediction
- Use cross-entropy loss with dropout regularization (probability = 0.2)
- Train with sequence length limit of 512 tokens, truncating longer sequences [9]
Inference and Data Extraction
- Apply trained NER model to polymer-relevant abstracts
- Implement heuristic rules to combine entity predictions into structured property records
- Export extracted data in structured format (e.g., JSON, database) [9]
Validation and Quality Assessment
- Evaluate model performance on held-out test set
- Measure inter-annotator agreement for training data (reported Fleiss Kappa = 0.885)
- Manually verify sample extractions for accuracy [9]
Protocol 2: LLM-Based Pipeline for Full-Text Extraction
This protocol describes a framework for extracting polymer-property data from full-text journal articles using large language models, capable of processing millions of paragraphs with high precision [1].
Research Reagent Solutions
Table 3: Essential Components for LLM-Based Extraction Pipeline
| Component | Function | Implementation Example |
|---|---|---|
| Full-Text Corpus | Comprehensive source data | 2.4 million journal articles from 11 publishers [1] |
| LLM for Information Extraction | Primary extraction engine | GPT-3.5 or LlaMa 2 [1] |
| Heuristic Filter | Initial relevance filtering | Property-specific keyword matching [1] |
| NER Filter | Verification of extractable records | MaterialsBERT-based entity detection [1] |
| Cost Optimization Framework | Manages computational expense | Two-stage filtering to reduce LLM calls [1] |
Step-by-Step Methodology
Corpus Assembly and Preparation
- Collect full-text articles from multiple publishers (Elsevier, Wiley, Springer Nature, etc.)
- Identify polymer-relevant documents through keyword search in titles and abstracts ("poly")
- Process documents at paragraph level (23.3 million paragraphs from 681,000 articles) [1]
Two-Stage Filtering System
- Apply property-specific heuristic filters to identify paragraphs mentioning target properties
- Utilize NER filter to verify presence of required entities (material, property, value, unit)
- This two-stage process reduced processing volume from 23.3M to 716,000 paragraphs (~3%) [1]
LLM Configuration and Prompt Engineering
- Select appropriate LLM (GPT-3.5 or LlaMa 2 in the reference implementation)
- Implement few-shot learning with task-specific examples
- Design prompts to extract structured property records from filtered paragraphs [1]
Structured Data Extraction and Validation
- Process filtered paragraphs through LLM to extract property records in structured format
- Implement consistency checks across extractions
- Resolve conflicting or ambiguous extractions through consensus mechanisms [1]
Performance and Cost Optimization
- Monitor extraction quality across different property types
- Optimize prompt strategies to maximize information yield per LLM call
- Balance computational cost against data quality requirements [1]
Comparative Performance Analysis
Quantitative Assessment of Extraction Approaches
Table 4: Performance Comparison of NLP Extraction Methods
| Metric | NER-Based Pipeline (Abstracts) | LLM-Based Pipeline (Full-Text) |
|---|---|---|
| Processing Scale | ~130,000 abstracts | ~681,000 full-text articles |
| Extraction Output | ~300,000 property records | >1 million property records |
| Properties Covered | Multiple property types | 24 specific properties |
| Processing Time | 60 hours | Not specified |
| Key Innovation | MaterialsBERT domain adaptation | Two-stage filtering with LLM extraction |
| Primary Advantage | Computational efficiency | Comprehensive full-text coverage |
| Limitations | Restricted to abstracts | Higher computational cost |
The comparative analysis reveals complementary strengths between traditional NER-based approaches and emerging LLM-based methods. NER pipelines offer computational efficiency and domain specificity, while LLM approaches provide broader coverage and greater flexibility [1] [9]. The two-stage filtering system implemented in the LLM pipeline proved particularly effective, reducing the number of paragraphs requiring expensive LLM processing from 23.3 million to approximately 716,000 (3% of the original corpus) while maintaining comprehensive coverage of extractable data [1].
Implementation Toolkit for Materials Researchers
NLP Tools and Frameworks
Table 5: NLP Tools for Materials Science Applications
| Tool | Type | Materials Science Applications |
|---|---|---|
| spaCy | Open-source library | Fast NLP pipelines for entity recognition and dependency parsing [11] |
| Hugging Face Transformers | Model repository | Access to pretrained models (BERT, GPT) for materials text [11] |
| MaterialsBERT | Domain-specific model | NER for materials science texts [9] |
| ChemDataExtractor | Domain-specific toolkit | Extraction of chemical information from scientific literature [9] |
| Stanford CoreNLP | Java-based toolkit | Linguistic analysis of materials science texts [11] |
Practical Implementation Considerations
Successful implementation of NLP pipelines for materials research requires attention to several practical considerations:
Data Quality and Preprocessing: The quality of extracted data heavily depends on proper text preprocessing, including cleaning, tokenization, and normalization. Materials science texts present particular challenges with specialized terminology, non-standard nomenclature, and ambiguous abbreviations [1].
Domain Adaptation: General-purpose NLP models typically underperform on materials science texts due to domain-specific terminology. Effective implementation requires domain adaptation through continued pretraining on scientific corpora (as with MaterialsBERT) or fine-tuning on annotated materials science datasets [8] [9].
Computational Resource Management: LLM-based approaches offer powerful extraction capabilities but require significant computational resources. Implementation strategies should include filtering mechanisms to reduce unnecessary LLM calls and cost-benefit analysis of extraction precision requirements [1].
Integration with Materials Informatics Workflows: Extracted data should be formatted for seamless integration with downstream materials informatics applications, including property prediction models, materials discovery frameworks, and data visualization platforms [8] [9].
Future Directions and Challenges
The application of NLP in materials science continues to evolve rapidly, with several emerging trends and persistent challenges shaping future development:
Multimodal AI Systems: Next-generation systems are incorporating multimodal capabilities that process not only text but also figures, tables, and molecular structures from scientific literature [6].
Domain-Specialized LLMs: There is growing development of materials-specialized LLMs trained specifically for polymer science, metallurgy, ceramics, and other subdomains to improve accuracy and relevance compared to general-purpose models [6].
Autonomous Research Systems: NLP technologies are increasingly integrated into autonomous research systems that combine literature analysis with experimental planning and execution [8].
Persistent Challenges: Significant challenges remain in handling the complexity of materials science nomenclature, ensuring extraction accuracy, mitigating LLM "hallucinations," and managing computational costs [1] [6]. Additionally, the extraction of synthesis parameters and processing-structure-property relationships presents more complex challenges than simple property extraction [8].
As NLP technologies continue to mature, their integration into materials research workflows promises to accelerate discovery cycles, enhance data-driven materials design, and ultimately transform how researchers extract knowledge from the vast and growing materials science literature.
Key Polymer Data Types Locked in Unstructured Text
The field of polymer science is experiencing rapid growth, with the number of published materials science papers increasing at a compounded annual rate of 6% [9]. This ever-expanding volume of literature contains a wealth of quantitative and qualitative material property information locked away in natural language that is not machine-readable [9]. This data scarcity in materials informatics impedes the training of property predictors, which traditionally requires painstaking manual curation of data from literature [9]. The emerging field of polymer informatics addresses this challenge by leveraging artificial intelligence (AI) and machine learning (ML) to enable data-driven research, moving beyond traditional intuition- and trial-and-error-based methods [12]. Natural language processing (NLP) presents a transformative opportunity to automatically extract this locked information, infer complex chemistry-structure-property relationships, and accelerate the discovery of novel polymers with tailored characteristics for specific applications.
Key Polymer Data Types and Extraction Ontology
To systematically extract information from polymer literature, a defined ontology is required. The following table summarizes key entity types used in a general-purpose polymer data extraction pipeline, which can capture the essential chemistry-structure-property relationships from scientific text [9].
Table 1: Key Polymer Data Types for NLP Extraction
| Entity Type | Description | Example |
|---|---|---|
| POLYMER | Specific named polymer entities | "polyethylene", "polymethacrylamide" |
| POLYMER_CLASS | Categories or families of polymers | "polyimide", "polynorbornene" |
| PROPERTY_NAME | Name of a measured or discussed property | "glass transition temperature", "ionic conductivity" |
| PROPERTY_VALUE | Numerical value and units associated with a property | "8.3 J cc⁻¹", "180 °C" |
| MONOMER | Building block or repeating unit of a polymer | "methacrylamide" |
| ORGANIC_MATERIAL | Other named organic substances in the system | "CTCA" (RAFT agent) |
| INORGANIC_MATERIAL | Named inorganic substances in the system | "lithium salt" |
| MATERIAL_AMOUNT | Quantity of a material used in a formulation | "5 wt%" |
This ontology forms the foundation for named entity recognition (NER) models, enabling the identification and categorization of critical information snippets from unstructured text [9]. The inter-annotator agreement for this ontology, with a Fleiss Kappa of 0.885, indicates good homogeneity and reliability for training machine learning models [9].
Experimental Protocol: Building a Polymer NLP Pipeline
This protocol details the steps for creating a natural language processing pipeline to extract structured polymer property data from scientific literature abstracts, based on the methodology established by Shetty et al. [9].
Materials and Software Requirements
Table 2: Research Reagent Solutions for Polymer NLP
| Item | Function/Description | Example/Source |
|---|---|---|
| Corpus of Text | Raw textual data for model training and processing. | 2.4 million materials science abstracts [9]. |
| Annotation Tool | Software for manual labeling of entity types in text. | Prodigy (https://prodi.gy) [9]. |
| Pre-trained Language Model | Base model for transfer learning and contextual embeddings. | PubMedBERT, SciBERT, or general BERT [9]. |
| Polymer-specific Language Model | Domain-adapted model for superior performance. | MaterialsBERT (trained on 2.4M materials science abstracts) [9]. |
| Computational Framework | Library for implementing neural network models. | PyTorch or TensorFlow. |
Step-by-Step Procedure
- Corpus Collection and Pre-processing: Begin with a large corpus of materials science abstracts. Filter for polymer-relevant content using keyword searches (e.g., "poly") and regular expressions to identify abstracts containing numerical data likely to represent property values [9].
- Annotation and Training Set Creation: Manually annotate a subset of abstracts (e.g., 750) using the defined ontology (Table 1). This process is ideally performed by multiple domain experts to ensure consistency. Split the annotated data into training (85%), validation (5%), and test (10%) sets [9].
- Model Architecture and Training:
- Encoder: Use a BERT-based model (e.g., MaterialsBERT) to convert input text tokens into context-aware vector embeddings [9].
- Classifier: Feed the generated token representations into a linear layer connected to a softmax non-linearity. This layer predicts the probability of each entity type for every input token [9].
- Training: Train the model using a cross-entropy loss function to learn the correct entity type labels. Use dropout (e.g., probability of 0.2) in the linear layer to prevent overfitting [9].
- Inference and Data Record Creation: Apply the trained NER model to the entire corpus of polymer abstracts. Use heuristic rules to combine the model's predictions (e.g., linking a PROPERTYVALUE to its corresponding PROPERTYNAME and POLYMER) to form complete material property records [9].
- Validation and Analysis: Manually review a sample of the extracted data to validate accuracy. The extracted dataset can then be used for analysis, trend identification, or as training data for property prediction models [9].
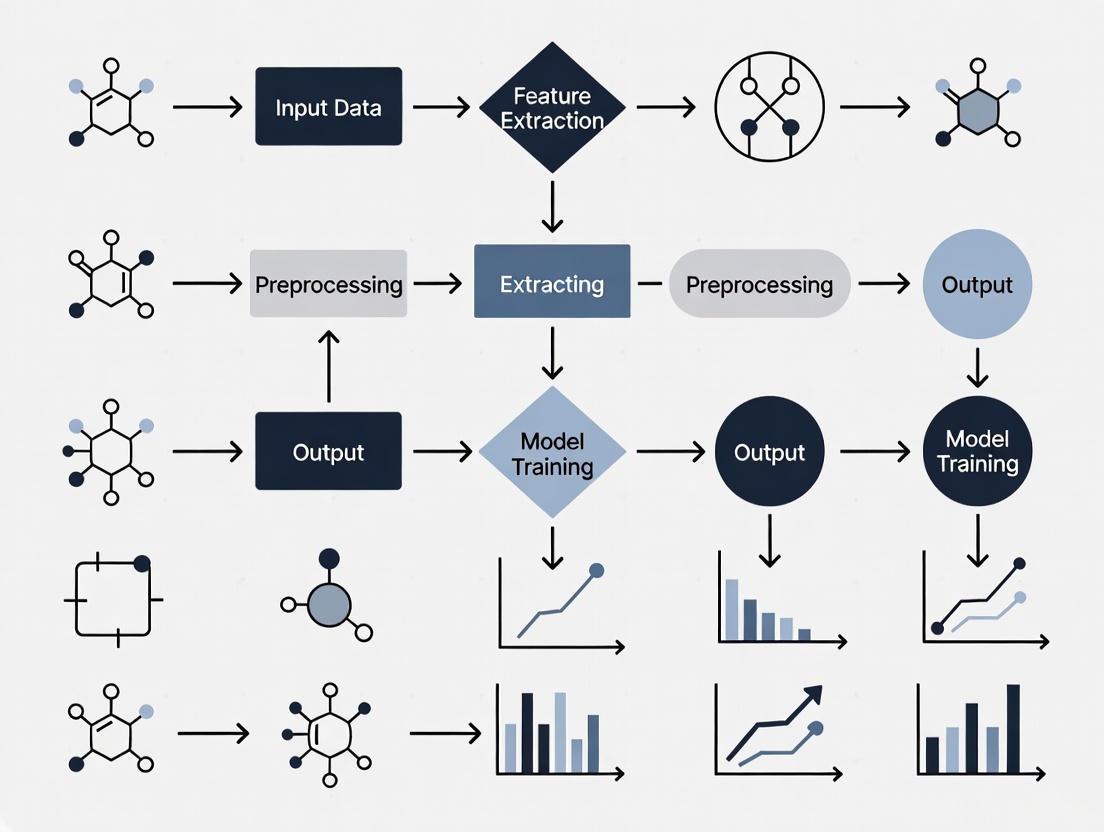
Figure 1: Polymer Data Extraction NLP Pipeline
Application Examples and Extracted Data Insights
The following table presents quantitative data extracted using the described NLP pipeline, showcasing its ability to recover non-trivial insights across diverse polymer applications [12] [9].
Table 3: Experimentally Derived Polymer Property Data from NLP Extraction
| Polymer/System | Application | Key Property Extracted | Property Value | Reference |
|---|---|---|---|---|
| PONB-2Me5Cl (Polymer) | Energy Storage Dielectrics | Energy Density @ 200°C | 8.3 J cc⁻¹ | [12] |
| Polymer Electrolyte Formulations | Li-Ion Batteries | Ionic Conductivity | High-conductivity candidates identified from 20k screenings | [12] |
| Doped Conjugated Polymers | Electronics | Electrical Conductivity | ~25 to 100 S/cm (Classification) | [12] |
| Polymer Membranes | Fluid Separation | Mixture Separation Precision | High precision forecast for crude oils | [12] |
| Polyesters & Polycarbonates | Biodegradable Polymers | Biodegradability Prediction Accuracy | >82% | [12] |
Advanced Model Architecture: From NER to Relation Extraction
The core of the extraction pipeline is a sophisticated neural model that builds upon the transformer architecture. The following diagram details the components involved in processing text to identify and classify polymer data entities.
Figure 2: NER Model Architecture for Polymer Data
Future Outlook and Emerging Techniques
The field of polymer informatics is rapidly evolving beyond basic NER. New deep learning frameworks are being developed to better capture the unique complexities of polymer chemistry. For instance, the PerioGT framework introduces a periodicity-aware deep learning approach that constructs a chemical knowledge-driven periodicity prior during pre-training and incorporates it into the model through contrastive learning [13]. This addresses a key limitation of existing methods that often simplify polymers into single repeating units, thereby neglecting their inherent periodicity and limiting model generalizability [13]. PerioGT has demonstrated state-of-the-art performance on 16 downstream tasks and successfully identified two polymers with potent antimicrobial properties in wet-lab experiments, highlighting the real-world potential of these advanced NLP and AI methods [13]. The integration of such sophisticated models will further enhance the accuracy and scope of data extraction, pushing the boundaries of data-driven polymer discovery.
The Shift from Manual Curation to Automated Extraction
The field of polymer science is experiencing rapid growth, with published literature expanding at a compounded annual rate of 6% [9]. This ever-increasing volume of scientific publications has made the traditional method of manual data curation a significant bottleneck. Manually inferring chemistry-structure-property relationships from literature is not only time-consuming but also prone to inconsistencies, creating a data scarcity that stifles machine learning (ML) applications and delays the discovery of next-generation energy materials [14] [9]. The shift from manual curation to automated extraction using Natural Language Processing (NLP) and Large Language Models (LLMs) is therefore critical to unlocking the vast amount of structured data trapped in unstructured text, thereby accelerating materials discovery and innovation.
Quantitative Comparison: Manual vs. Automated Extraction
The advantages of automated data extraction systems over manual methods are substantial and measurable. The table below summarizes a direct comparison in the context of clinical data, which mirrors the efficiencies found in scientific data extraction, demonstrating dramatic improvements in processing time and resource utilization [15].
| Parameter | Manual Review | LLM-Based Processing |
|---|---|---|
| Processing Time | 7 months (5 physicians) | 12 days (2 physicians) |
| Physician Hours | 1025 hours | 96 hours |
| Resource Reduction | Baseline | 91% reduction in hours |
| Accuracy | Baseline for comparison | 90.8% |
| Cost per Case | Labor-intensive | ~US $0.15 (API cost) |
| Key Advantage | Human judgment | Efficiency, scalability, consistency |
In polymer science, the scale of automation is even more profound. One study processed ~130,000 abstracts in just 60 hours, obtaining approximately 300,000 material property records [9]. A more extensive effort on full-text articles utilized a corpus of 2.4 million materials science journal articles, identifying 681,000 polymer-related documents and extracting over one million property records for over 106,000 unique polymers [1]. This demonstrates the unparalleled scalability of automated pipelines.
Experimental Protocols for Automated Extraction
Implementing an effective automated data extraction pipeline requires a structured methodology. The following protocols detail two proven approaches.
Protocol A: LLM-Based Processing Pipeline
This protocol leverages the powerful reasoning capabilities of large language models like GPT-3.5 or Claude 3.5 Sonnet for direct data extraction and structuring [1] [15].
Workflow Overview:
Detailed Steps:
- Document Retrieval & Pre-processing: Assemble a corpus of full-text journal articles or abstracts. Identify polymer-relevant documents by searching for domain-specific terms (e.g., "poly") in titles and abstracts [1].
- Two-Stage Text Filtering: To optimize costs and efficiency, a dual-stage filter is applied to the text paragraphs:
- Heuristic Filter: Pass each paragraph through property-specific filters using manually curated keywords and co-referents to identify texts relevant to target properties (e.g., "glass transition", "Young's modulus"). This typically reduces the text volume to ~11% of the original [1].
- NER Filter: Apply a Named Entity Recognition (NER) model, such as MaterialsBERT, to the remaining paragraphs to confirm the presence of all necessary entities (e.g.,
POLYMER,PROPERTY_NAME,PROPERTY_VALUE,UNIT). This further refines the dataset to ~3% of the original paragraphs, ensuring they contain complete, extractable records [1].
- LLM Prompting & Data Structuring: Feed the filtered paragraphs into an LLM using a carefully designed prompt. The prompt should be developed iteratively over multiple phases (e.g., initial framework, rule refinement, edge-case handling) with sample data to instruct the model on how to extract and structure the required factors into a predefined format like CSV [15] [1].
- Data Validation & Integration: A stratified random sample of the LLM outputs should be validated by domain experts to assess accuracy. The final structured data is then integrated into a searchable database or used for downstream ML tasks [15] [9].
Protocol B: Specialized NER Model Pipeline
This protocol involves training or utilizing a domain-specific BERT model, which is highly effective for large-scale, general-purpose property extraction [9].
Workflow Overview:
Detailed Steps:
- Corpus Creation: Gather a large collection of materials science abstracts or full-text articles (e.g., 2.4 million papers) [9] [1].
- Ontology Definition & Annotation: Define an ontology of entity types relevant to polymer science (e.g.,
POLYMER,PROPERTY_NAME,PROPERTY_VALUE,MONOMER). Domain experts then annotate a subset of documents (e.g., 750 abstracts) using this ontology to create a labeled training dataset [9]. - Model Training: Train a NER model using a BERT-based architecture. A model like MaterialsBERT, which is pre-trained on millions of materials science abstracts, is fine-tuned on the annotated dataset. This model learns to tag tokens in the text with the correct entity labels from the ontology [9].
- Inference & Relation Extraction: Apply the trained NER model to the entire unlabeled corpus. Use heuristic rules and dependency parsing to combine the predicted entities and establish relationships between them, forming complete material-property-value records [9].
- Data Output & Analysis: The extracted data is made available in a structured format and can be analyzed for specific applications, such as identifying trends in polymer solar cells or fuel cells, or for training property prediction models [9].
The following table catalogues the key computational tools and data sources that form the foundation of modern, automated polymer data extraction workflows.
| Tool/Resource Name | Type | Function in Automated Extraction |
|---|---|---|
| MaterialsBERT [1] [9] | Domain-Specific Language Model | A BERT model pre-trained on materials science text; excels at Named Entity Recognition (NER) for identifying materials and properties. |
| GPT-3.5 / LlaMa 2 [1] | General-Purpose LLM | Used for direct information extraction and structuring from text via API calls, leveraging few-shot learning. |
| Claude 3.5 Sonnet [15] | General-Purpose LLM | An alternative LLM used for curating and structuring data from pre-extracted, deidentified clinical data sheets. |
| Polymer Scholar [1] [9] | Public Data Repository | A web-based interface hosting millions of automatically extracted polymer-property records for the research community. |
| Clinical Data Warehouse (CDW) [15] | Structured Data Source | An integrated data platform that provides pre-extracted, deidentified clinical data for subsequent LLM processing. |
The shift from manual curation to automated extraction is no longer a future prospect but an ongoing transformation in polymer and materials research. Methodologies leveraging both specialized NER models like MaterialsBERT and powerful general-purpose LLMs have proven their ability to process millions of documents with remarkable efficiency and accuracy. This paradigm shift addresses the critical data scarcity problem, enabling the creation of large-scale, structured datasets. These datasets are indispensable for training robust machine learning models, uncovering non-trivial insights from existing literature, and ultimately accelerating the design and discovery of novel polymer materials for energy and other advanced technologies.
The exponential growth of published materials science literature presents a significant bottleneck for research, with the number of papers increasing at a compounded annual rate of 6% [9]. Within this domain, polymer science faces unique informatics challenges due to non-standard nomenclature, complex material representations, and the unstructured nature of data trapped in scientific texts [9] [1]. Natural language processing (NLP) offers promising solutions to automatically extract structured polymer-property data from published literature, enabling large-scale data analysis and accelerating materials discovery [9] [1] [8]. This application note examines the specific challenges in polymer data extraction and details experimental protocols for overcoming them, framed within the broader context of NLP for polymer informatics.
Domain-Specific Challenges in Polymer Data Extraction
Polymer Name Variations and Normalization
Polymer nomenclature presents unique challenges distinct from small molecules or inorganic materials. Polymers exhibit non-trivial variations in naming conventions, including commonly used names, acronyms, synonyms, and historical terms [9] [1]. For instance, the polymer poly(methyl methacrylate) might be referred to as PMMA, acrylic glass, or perspex across different publications. This variability necessitates robust normalization techniques to identify all name variations referring to the same polymer entity.
Unlike small organic molecules, polymer names cannot typically be converted to standardized representations like SMILES strings without additional structural inference from figures or supplementary information [9]. This limitation complicates the training of property-predictor machine learning models that require structured input representations.
Property Normalization and Relationship Extraction
Material property information in scientific literature exhibits substantial variability in expression, units, and measurement contexts. Different authors may report the same property using different terminology, units, or numerical formats. For example, glass transition temperature might be referred to as "Tg," "glass transition temperature," or "glass transition point" across different abstracts [9].
Establishing accurate relationships between extracted entities (polymers, properties, values, and conditions) presents additional challenges, particularly when information spans multiple sentences or includes comparative statements [1]. Traditional named entity recognition (NER) systems can identify individual entities but struggle with connecting these entities into meaningful property records without additional relationship extraction capabilities.
Quantitative Performance Analysis
Table 1: Performance comparison of NLP approaches for polymer data extraction
| Method | Data Source | Records Extracted | Processing Time | Key Advantages |
|---|---|---|---|---|
| MaterialsBERT (NER) | 130,000 abstracts | ~300,000 [9] | 60 hours [9] | Cost-effective; materials-specific training |
| LLM-based (GPT-3.5) | 681,000 full-text articles | >1,000,000 [1] | Not specified | Superior relationship extraction; handles complex contexts |
| Manual Curation (PoLyInfo) | Various sources | ~492,000 [16] | Many years [16] | High precision; expert validation |
Table 2: Property prediction performance using extracted polymer data
| Property | Best Model | R² Value | Impact of Textual Modality |
|---|---|---|---|
| Glass Transition Temperature (Tg) | Uni-Poly | ~0.90 [17] | Minimal improvement |
| Thermal Decomposition Temperature (Td) | Uni-Poly | 0.70-0.80 [17] | ~1.6-3.9% R² improvement [17] |
| Density (De) | Uni-Poly | 0.70-0.80 [17] | ~1.6-3.9% R² improvement [17] |
| Electrical Resistivity (Er) | Uni-Poly | 0.40-0.60 [17] | ~1.6-3.9% R² improvement [17] |
| Melting Temperature (Tm) | Uni-Poly | 0.40-0.60 [17] | ~1.6-3.9% R² improvement [17] |
Experimental Protocols
Named Entity Recognition with MaterialsBERT
Objective: To extract polymer-related entities from scientific abstracts using a domain-specific language model.
Materials and Methods:
- Corpus: 2.4 million materials science abstracts [9]
- Annotation Tool: Prodigy
- Annotation Guidelines: 8 entity types (POLYMER, POLYMERCLASS, PROPERTYVALUE, PROPERTYNAME, MONOMER, ORGANICMATERIAL, INORGANICMATERIAL, MATERIALAMOUNT) [9]
- Training Data: 750 manually annotated abstracts (85% training, 5% validation, 10% testing) [9]
- Model Architecture: BERT-based encoder with linear layer and softmax non-linearity [9]
- Training Parameters: Cross-entropy loss, dropout probability of 0.2, sequence length limit of 512 tokens [9]
Procedure:
- Filter polymer-relevant abstracts using keyword "poly" and regular expressions for numeric information [9]
- Pre-annotate abstracts using entity dictionaries to accelerate manual annotation [9]
- Conduct three rounds of annotation with guideline refinement between rounds [9]
- Train MaterialsBERT model using transfer learning from PubMedBERT [9]
- Evaluate model performance using standard NER metrics on test set [9]
LLM-Based Data Extraction from Full-Text Articles
Objective: To extract polymer-property records from full-text journal articles using large language models.
Materials and Methods:
- Corpus: 2.4 million materials science journal articles from 11 publishers [1]
- LLM Models: GPT-3.5 and LlaMa 2 [1]
- Target Properties: 24 polymer properties including thermal, optical, mechanical, and transport properties [1]
- Filtering System: Two-stage approach (heuristic filter + NER filter) [1]
Procedure:
- Identify polymer-related documents (681,000) by searching for "poly" in titles and abstracts [1]
- Divide articles into paragraphs (23.3 million total) [1]
- Apply property-specific heuristic filters to identify relevant paragraphs (~2.6 million) [1]
- Apply NER filter to confirm presence of complete extractable records (~716,000 paragraphs) [1]
- Process filtered paragraphs through LLMs with appropriate prompting strategies [1]
- Validate extracted records and format into structured database [1]
Workflow Visualization
Diagram 1: Polymer data extraction workflow from full-text articles
Diagram 2: Named entity recognition model architecture
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential resources for polymer data extraction research
| Resource | Type | Function | Access |
|---|---|---|---|
| MaterialsBERT | Language Model | Domain-specific NER for materials science [9] | Publicly available |
| Polymer Scholar | Data Platform | Explore extracted polymer property data [9] [1] | polymerscholar.org |
| Poly-Caption | Dataset | Textual descriptions of polymers for multi-modal learning [17] | Generated via knowledge-enhanced prompting |
| PoLyInfo | Database | Manually curated polymer data for validation [16] | Public database |
| Uni-Poly | Framework | Multi-modal polymer representation learning [17] | Research implementation |
The challenges of polymer name variations and property normalization represent significant but addressable bottlenecks in polymer informatics. The integration of domain-specific NER models like MaterialsBERT with the emergent capabilities of large language models creates a powerful paradigm for unlocking the vast knowledge repository contained in polymer literature [9] [1]. The experimental protocols detailed in this application note provide researchers with practical methodologies for implementing these approaches, while the quantitative performance analyses offer realistic expectations for extraction outcomes. As these technologies mature, they promise to accelerate polymer discovery and design by creating large-scale, structured datasets amenable to machine learning and data-driven materials development.
Building NLP Pipelines for Polymer Informatics: From BERT to Applications
Architecture of a General-Purpose Polymer Data Extraction Pipeline
The exponential growth of polymer science literature presents a significant challenge for researchers seeking to extract structured property data from vast quantities of unstructured text. Natural language processing (NLP) and large language models (LLMs) have emerged as transformative technologies to address this challenge, enabling the automated construction of large-scale materials databases [8]. This application note details the architecture of a general-purpose pipeline for extracting polymer-property data from scientific literature, framing the methodology within broader research on NLP for polymer informatics. The described pipeline processes a corpus of 2.4 million materials science articles to identify polymer-related content and extract structured property records [1], providing researchers with a scalable solution for materials data acquisition.
The polymer data extraction pipeline employs a modular architecture that combines rule-based filtering with advanced machine learning models to identify, process, and structure polymer-property information from full-text journal articles. The overall workflow, illustrated in Figure 1, processes individual paragraphs as text units to maximize contextual understanding and relationship detection between material entities and their properties [1].
Figure 1. General Architecture of Polymer Data Extraction Pipeline. The pipeline processes millions of journal articles through sequential filtering stages to identify polymer-property relationships and output structured data [1].
Pipeline Components and Methodologies
Data Acquisition and Polymer Filtering
The initial stage involves assembling a comprehensive corpus of materials science literature and filtering for polymer-relevant content. The corpus construction utilizes authorized downloads from 11 major publishers, including Elsevier, Wiley, Springer Nature, American Chemical Society, and the Royal Society of Chemistry [1].
Table 1: Data Acquisition and Initial Filtering Statistics
| Processing Stage | Scale | Filtering Method | Output |
|---|---|---|---|
| Initial Corpus | 2.4 million articles | Crossref indexing | Full document collection |
| Polymer Filtering | 681,000 articles | 'poly' string search in title/abstract | Polymer-related documents |
| Paragraph Processing | 23.3 million paragraphs | Text unit segmentation | Processable text units |
Experimental Protocol: Corpus Assembly and Polymer Filtering
- Data Collection: Access full-text articles through publisher APIs with appropriate authentication and licensing.
- Text Extraction: Convert articles from PDF/XML formats to plain text, preserving paragraph structure.
- Polymer Filtering: Apply string-based filtering using the term 'poly' in titles and abstracts to identify polymer-relevant documents.
- Paragraph Segmentation: Process each document into discrete paragraphs, treating each as an independent text unit for downstream processing.
Two-Stage Text Filtering System
The pipeline implements a dual-stage filtering approach to identify paragraphs containing extractable polymer-property data while minimizing computational costs associated with processing irrelevant text [1].
Figure 2. Two-Stage Paragraph Filtering System. The heuristic filter identifies property-relevant text, while the NER filter confirms the presence of complete, extractable records [1].
Experimental Protocol: Heuristic Filtering
- Property List Definition: Identify 24 target polymer properties based on significance and downstream application needs (Table 2).
- Keyword Dictionary Creation: Manually curate property-specific keywords and co-referents through literature review.
- Paragraph Scoring: Implement regular expressions to flag paragraphs containing property mentions.
- Result Compilation: Collect approximately 2.6 million paragraphs (11% of original) that pass heuristic filters.
Experimental Protocol: Named Entity Recognition (NER) Filtering
- Entity Definition: Configure the NER model to detect four critical entity types: material name, property name, property value, and unit.
- Model Application: Process heuristic-filtered paragraphs through MaterialsBERT to identify paragraphs containing all required entities.
- Completeness Verification: Select only paragraphs with complete entity sets (all four entity types present) for downstream extraction.
- Output Generation: Produce a refined set of approximately 716,000 paragraphs (3% of original) with verified extractable records.
Data Extraction Models and Methodologies
The pipeline employs multiple natural language processing models for data extraction, each with distinct strengths and optimization characteristics [1].
Table 2: Performance Comparison of Data Extraction Models
| Model | Architecture | Parameters | Extraction Quantity | Quality Metrics | Computational Cost |
|---|---|---|---|---|---|
| MaterialsBERT | Transformer-based NER | ~110M (base) | ~300K records from abstracts | F1: 0.885 (PolymerAbstracts) | Lower inference cost |
| GPT-3.5 | Generative LLM | 175B | >1M records from full-text | High precision with few-shot learning | Significant API costs |
| LlaMa 2 | Open-source LLM | 7B-70B | Comparable to GPT-3.5 | Competitive with commercial LLMs | High hardware requirements |
Experimental Protocol: MaterialsBERT Implementation
- Model Selection: Utilize MaterialsBERT, a BERT-based model pre-trained on 2.4 million materials science abstracts [9].
- Fine-Tuning: Adapt the base model using the PolymerAbstracts dataset (750 annotated abstracts) for polymer-specific entity recognition.
- Entity Annotation: Implement an 8-class ontology: POLYMER, POLYMERCLASS, PROPERTYVALUE, PROPERTYNAME, MONOMER, ORGANICMATERIAL, INORGANICMATERIAL, MATERIALAMOUNT.
- Training Configuration: Use cross-entropy loss, dropout (p=0.2), and sequence truncation at 512 tokens.
- Inference: Process filtered paragraphs to extract structured property records.
Experimental Protocol: LLM-Based Extraction (GPT-3.5/LlaMa 2)
- Prompt Engineering: Design few-shot learning prompts with task-specific examples to guide extraction.
- API Integration: Configure API calls with appropriate parameters (temperature, max_tokens) for structured output.
- Output Parsing: Implement post-processing to convert LLM responses to structured format.
- Cost Optimization: Batch process paragraphs and implement caching to reduce API calls.
Target Polymer Properties
The pipeline is configured to extract 24 key polymer properties selected for their significance in materials informatics and application relevance [1].
Table 3: Target Polymer Properties for Extraction
| Property Category | Specific Properties | Application Relevance |
|---|---|---|
| Thermal Properties | Glass transition temperature, Melting point, Thermal stability | Polymer processing, application temperature range |
| Mechanical Properties | Tensile strength, Elastic modulus, Toughness | Structural applications, material selection |
| Optical Properties | Refractive index, Bandgap, Transparency | Dielectric aging, breakdown, optoelectronics |
| Transport Properties | Gas permeability, Ionic conductivity | Filtering, distillation, energy applications |
| Solution Properties | Intrinsic viscosity, Solubility parameters | Solution processing, formulation design |
Successful implementation of the polymer data extraction pipeline requires specific computational resources and software tools.
Table 4: Essential Research Reagents and Computational Resources
| Resource Category | Specific Tools/Resources | Function in Pipeline |
|---|---|---|
| Language Models | MaterialsBERT, GPT-3.5, LlaMa 2 | Core extraction capabilities for text understanding |
| Computational Framework | Python, PyTorch/TensorFlow | Model implementation and training |
| Data Processing | SpaCy, NLTK, Pandas | Text preprocessing and data manipulation |
| Orchestration | Apache Airflow, Prefect | Workflow management and scheduling |
| Data Storage | Data warehouses (BigQuery), Data lakes (S3) | Structured and unstructured data storage |
| Annotation Tools | Prodigy, Label Studio | Manual annotation for model training |
This application note has detailed the architecture and implementation protocols for a general-purpose polymer data extraction pipeline that successfully processes millions of scientific articles to construct structured polymer-property databases. The modular design, combining heuristic filtering with advanced NLP models, demonstrates the feasibility of large-scale automated data extraction from materials science literature. The pipeline has been validated through the extraction of over one million property records for more than 106,000 unique polymers, creating a valuable resource for materials informatics and accelerating polymer discovery and design. The methodologies described provide researchers with a comprehensive framework for implementing similar data extraction capabilities in their own polymer informatics research.
The ever-increasing number of materials science articles, growing at a rate of 6% compounded annually, makes it increasingly challenging to infer chemistry-structure-property relations from literature manually [9]. This data scarcity in materials informatics stems from quantitative material property information being "locked away" in publications written in natural language that is not machine-readable [9]. To address this challenge, researchers have developed MaterialsBERT, a domain-specific language model trained on millions of materials science abstracts to enable automated data extraction from scientific literature [9].
MaterialsBERT represents a specialized adaptation of the BERT (Bidirectional Encoder Representations from Transformers) architecture, pre-trained specifically on materials science text corpora [9]. Unlike general-purpose language models, MaterialsBERT understands materials-specific notations, jargons, and the complex nomenclature system used in polymer science, including commonly used names, acronyms, synonyms, and historical terms [1]. This domain specialization enables superior performance in natural language processing (NLP) tasks specific to materials science, particularly for polymer data extraction.
Table: Comparison of Domain-Specific BERT Models for Scientific Applications
| Model Name | Base Architecture | Training Corpus | Primary Domain | Key Applications |
|---|---|---|---|---|
| MaterialsBERT | PubMedBERT | 2.4M materials science abstracts [9] | Materials Science (Polymers) | Property extraction, NER, relation classification |
| MatSciBERT | SciBERT | ~285M words from materials papers [18] | Materials Science (General) | NER, abstract classification, relation classification |
| BioBERT | BERT-base | Biomedical corpora [9] | Biomedical | Biomedical text mining |
| ChemBERT | BERT-base | Chemical literature [9] | Chemistry | Chemical entity recognition |
Model Architecture and Training Methodology
Base Architecture and Pre-training
MaterialsBERT builds upon the transformer-based BERT architecture, which has become the de facto solution for numerous NLP tasks [9]. The model embodies the transfer learning paradigm where a language model is pre-trained on massive corpora of unlabeled text using unsupervised objectives, then reused for specific NLP tasks. The resulting BERT encoder generates token embeddings for input text that are conditioned on all other input tokens, making them context-aware [9].
For MaterialsBERT, researchers initialized the model with PubMedBERT weights and continued pre-training on 2.4 million materials science abstracts [9]. This domain-adaptive pre-training approach follows methodologies established by models like BioBERT and FinBERT, where the base BERT model undergoes additional training on domain-specific text [18]. The vocabulary overlap between the materials science corpus and SciBERT vocabulary was approximately 53.64%, justifying the use of SciBERT as the foundation model [18].
Named Entity Recognition Architecture
The NER architecture employing MaterialsBERT uses a BERT-based encoder to generate representations for tokens in the input text [9]. These representations serve as inputs to a linear layer connected to a softmax non-linearity that predicts the probability of the entity type for each token. During training, the cross-entropy loss optimizes the entity type predictions, with the highest probability label selected as the predicted entity type during inference [9].
The model uses a dropout probability of 0.2 in the linear layer to prevent overfitting [9]. Since most abstracts fall within the BERT model's input sequence limit of 512 tokens, sequences exceeding this length are truncated as per standard practice [9].
Experimental Protocols and Annotation Framework
Corpus Construction and Annotation
The development of MaterialsBERT involved creating a specialized annotation framework tailored to polymer science. Researchers filtered a corpus of 2.4 million materials science papers to obtain polymer-relevant abstracts containing the string 'poly' and numeric information using regular expressions [9]. From this corpus, 750 abstracts were selected for manual annotation using a carefully designed ontology.
Table: Annotation Ontology for Polymer Data Extraction
| Entity Type | Description | Examples |
|---|---|---|
| POLYMER | Specific polymer names | "polyethylene", "PMMA" |
| POLYMER_CLASS | Categories or classes of polymers | "polyester", "nylon" |
| PROPERTY_VALUE | Numerical property values | "125", "0.45" |
| PROPERTY_NAME | Names of material properties | "glass transition temperature", "tensile strength" |
| MONOMER | Monomer units constituting polymers | "ethylene", "styrene" |
| ORGANIC_MATERIAL | Organic compounds and materials | "solvents", "additives" |
| INORGANIC_MATERIAL | Inorganic compounds and materials | "silica", "metal oxides" |
| MATERIAL_AMOUNT | Quantities of materials | "2 grams", "5 mol%" |
Annotation was performed by three domain experts using the Prodigy annotation tool over three iterative rounds [9]. With each round, annotation guidelines were refined, and previous abstracts were re-annotated using the updated guidelines. To assess inter-annotator agreement, 10 abstracts were annotated by all annotators, yielding a Fleiss Kappa of 0.885 and pairwise Cohen's Kappa values of (0.906, 0.864, 0.887), indicating strong annotation consistency [9].
The annotated dataset, termed PolymerAbstracts, was split into 85% for training, 5% for validation, and 10% for testing [9]. Prior to manual annotation, researchers automatically pre-annotated abstracts using entity dictionaries to expedite the annotation process [9].
Model Training and Evaluation
The training protocol for the NER model involved using the annotated PolymerAbstracts dataset with MaterialsBERT as the encoder. The model was trained to predict entity types for each token in the input sequence, with the cross-entropy loss function optimizing the predictions [9].
Evaluation compared MaterialsBERT against multiple baseline encoders across five named entity recognition datasets [9]. The training and evaluation settings remained identical across all encoders tested for each dataset to ensure fair comparison. MaterialsBERT demonstrated superior performance, outperforming other baseline models in three out of five NER datasets [9].
Data Extraction Pipeline and Implementation
End-to-End Extraction Workflow
The complete data extraction pipeline utilizing MaterialsBERT processes polymer literature through a multi-stage workflow [9] [1]. This pipeline begins with corpus collection, proceeds through text processing and entity recognition, and culminates in structured data output.
Full-Text Extraction with Hybrid Filtering
Recent advancements have extended MaterialsBERT to full-text article processing using a hybrid filtering approach [1]. This system processes 23.3 million paragraphs from 681,000 polymer-related articles through a dual-stage filtering mechanism:
Heuristic Filter: Applies property-specific patterns to identify paragraphs mentioning target polymer properties or co-referents, reducing the corpus from 23.3 million to approximately 2.6 million paragraphs (~11%) [1]
NER Filter: Utilizes MaterialsBERT to identify paragraphs containing all necessary named entities (material name, property name, property value, unit), further refining the corpus to about 716,000 paragraphs (~3%) containing complete extractable records [1]
This filtering strategy enables efficient processing of full-text articles while maintaining high-quality data extraction. The pipeline successfully extracted over one million records corresponding to 24 properties of more than 106,000 unique polymers from full-text journal articles [1].
Performance Analysis and Comparison
Quantitative Performance Metrics
The MaterialsBERT-based extraction pipeline demonstrated exceptional efficiency and scalability in processing polymer literature [9]. In benchmark tests, the system needed only 60 hours to extract approximately 300,000 material property records from about 130,000 abstracts [9] [19]. This extraction rate significantly surpasses manual curation efforts, as evidenced by comparison with the PoLyInfo database, which contains over 492,000 material property records manually curated over many years [19].
Table: Data Extraction Performance Comparison
| Extraction Method | Records Extracted | Source Documents | Processing Time | Primary Properties |
|---|---|---|---|---|
| MaterialsBERT (Abstracts) | ~300,000 [9] | ~130,000 abstracts [9] | 60 hours [9] | Multiple polymer properties |
| MaterialsBERT (Full-Text) | >1,000,000 [1] | ~681,000 articles [1] | Not specified | 24 targeted properties |
| Manual Curation (PoLyInfo) | ~492,000 [19] | Not specified | Many years [19] | Multiple polymer properties |
Comparison with LLM-Based Approaches
Recent studies have compared MaterialsBERT performance against large language models (LLMs) like GPT-3.5 and LlaMa 2 for polymer data extraction [1]. While LLMs offer competitive performance, MaterialsBERT provides a more computationally efficient solution for large-scale extraction tasks. Researchers evaluated these models across four critical performance categories: quantity, quality, time, and cost of data extraction [1].
The hybrid approach combining MaterialsBERT with LLMs represents the state-of-the-art, where MaterialsBERT serves as an effective filter to identify relevant paragraphs, reducing unnecessary LLM prompting and optimizing computational costs [1]. This combined approach leverages the precision of MaterialsBERT for entity recognition with the relationship extraction capabilities of LLMs.
Research Reagent Solutions
Implementing MaterialsBERT for polymer data extraction requires specific computational "reagents" and resources. The following table details the essential components and their functions in the research workflow.
Table: Essential Research Reagents for MaterialsBERT Implementation
| Component | Type | Function | Implementation Notes |
|---|---|---|---|
| MaterialsBERT Model | Pre-trained Language Model | Token embedding and entity recognition | Available from original research; based on PubMedBERT architecture [9] |
| PolymerAbstracts Dataset | Annotated Training Data | Model fine-tuning and evaluation | 750 manually annotated abstracts with 8 entity types [9] |
| Prodigy Annotation Tool | Software | Manual annotation of training data | Commercial tool; alternatives include BRAT or Doccano [9] |
| SciBERT Tokenizer | Text Processing | Vocabulary tokenization | Uses SciBERT vocabulary with 53.64% overlap to materials science corpus [18] |
| Polymer Scholar Platform | Database Interface | Data exploration and access | Web-based interface (polymerscholar.org) for accessing extracted data [9] |
| Full-Text Article Corpus | Data Source | Primary extraction material | 2.4 million materials science articles from multiple publishers [1] |
Applications and Impact
The data extracted through MaterialsBERT-powered pipelines has enabled diverse applications across polymer science. Researchers have analyzed the extracted data for applications including fuel cells, supercapacitors, and polymer solar cells, recovering non-trivial insights [9]. The structured data has also been used to train machine learning predictors for key properties like glass transition temperature [9].
The Polymer Scholar platform (polymerscholar.org) provides accessible exploration of extracted material property data, allowing researchers to locate material property information through keyword searches rather than manual literature review [9] [19]. This capability significantly accelerates materials research workflows and facilitates data-driven materials discovery.
Beyond immediate data extraction, the long-term vision for MaterialsBERT applications includes using the extracted data to train predictive models that can forecast material properties, ultimately enabling an extraordinary pace of materials discovery [19]. This pipeline represents a critical component in the emerging paradigm of data-driven materials science, where historical knowledge locked in literature becomes actionable for guiding future research directions.
The exponential growth of polymer science literature presents a significant challenge for researchers seeking to infer chemistry-structure-property relationships from published studies. Named Entity Recognition (NER) has emerged as a critical natural language processing (NLP) technique for automatically extracting and structuring polymer information from unstructured scientific text. This process involves identifying and classifying key entities—such as polymer names, property values, and material classes—into predefined categories to build machine-readable knowledge bases [9].
The development of specialized NER systems for polymer science addresses domain-specific challenges, including the expansive chemical design space of polymers and the prevalence of non-standard nomenclature featuring acronyms, synonyms, and historical terms [1]. Unlike small molecules, polymer names often cannot be directly converted to standardized representations like SMILES strings, requiring more sophisticated information extraction approaches [20]. This application note details the ontologies, methodologies, and practical protocols for implementing NER systems tailored to polymer science, enabling researchers to efficiently transform unstructured literature into structured, analyzable data.
Polymer NER Ontologies and Entity Definitions
Core Entity Types for Polymer Science
A well-defined ontology is fundamental to effective NER in specialized domains. The PolyNERE ontology and similar frameworks define entity types specifically designed to capture essential information from polymer literature [21]. These ontologies typically include the following core entity types:
Table 1: Core Entity Types in Polymer NER Ontologies
| Entity Type | Description | Example Phrases | Total Occurrences in PolymerAbstracts |
|---|---|---|---|
| POLYMER | Material entities that are polymers | "polyethylene", "PMMA", "nylon-6" | 7,364 |
| PROPERTY_NAME | Material property being described | "glass transition temperature", "tensile strength", "bandgap" | 4,535 |
| PROPERTY_VALUE | Numeric value and its unit corresponding to a material property | "165 °C", "45 MPa", "3.2 eV" | 5,800 |
| POLYMER_CLASS | Broad terms for classes of polymers | "polyolefins", "polyesters", "thermoplastics" | 1,476 |
| MONOMER | Repeat units for a POLYMER entity | "ethylene", "styrene", "methyl methacrylate" | 2,074 |
| INORGANIC_MATERIAL | Inorganic additives in polymer formulations | "silica nanoparticles", "montmorillonite clay" | 1,272 |
| ORGANIC_MATERIAL | Organic materials that are not polymers (plasticizers, cross-linkers) | "dioctyl phthalate", "dicumyl peroxide" | 914 |
| MATERIAL_AMOUNT | Amount of a particular material in a formulation | "30 wt%", "5 phr" | 1,143 |
This structured ontology enables the capture of complex polymer systems and their characteristics, facilitating the extraction of meaningful relationships between chemical structures, processing conditions, and resulting properties [20] [9]. The "OTHER" category serves as a default for tokens not belonging to these specific classes, representing 147,115 occurrences in the annotated PolymerAbstracts dataset [20].
Specialized NER Frameworks
The PolyNERE framework represents a recent advancement in polymer NER, featuring a novel ontology with multiple entity types, relation categories, and support for various NER settings [21]. This resource includes a high-quality NER and relation extraction corpus comprising 750 polymer abstracts annotated using their customized ontology. Distinctive features include the ability to assert entities and relations at different levels and providing supporting evidence to facilitate reasoning in relation extraction tasks [21].
Quantitative Performance Analysis of Polymer NER Methods
Comparison of Extraction Approaches
Recent research has evaluated multiple approaches for polymer data extraction, ranging from specialized NER models to general-purpose large language models (LLMs). The performance characteristics of these methods vary significantly across different metrics:
Table 2: Performance Comparison of Polymer Data Extraction Methods
| Extraction Method | Data Source | Extraction Scale | Key Performance Metrics | Limitations |
|---|---|---|---|---|
| MaterialsBERT (NER) | Abstracts | ~300,000 records from ~130,000 abstracts in 60 hours [20] | Superior to baseline models in 3/5 NER datasets [20] | Challenging entity relationships across extended passages [1] |
| GPT-3.5 & LlaMa 2 (LLM) | Full-text articles | >1 million records from 681,000 articles [1] | Effective for NER, classification, QA with limited datasets [1] | Significant computational costs and monetary expenses [1] |
| Hybrid Pipeline (NER + LLM) | Full-text paragraphs | 716,000 relevant paragraphs from 23.3 million total [1] | Extracted 24 properties for 106,000 unique polymers [1] | Requires careful filtering to optimize costs [1] |
Scale of Extracted Polymer Data
The implementation of automated NER systems has enabled the extraction of polymer data at unprecedented scales. One study processing a corpus of approximately 2.4 million materials science journal articles identified around 681,000 polymer-related articles, resulting in the extraction of over one million records corresponding to 24 properties of over 106,000 unique polymers [1]. This extracted polymer-property data has been made publicly available via the Polymer Scholar website (polymerscholar.org), providing researchers with access to structured polymer data for informatics applications [1] [20].
Experimental Protocols for Polymer NER
Corpus Annotation Protocol
Objective: To create a high-quality, annotated dataset for training and evaluating polymer NER models.
Materials and Tools:
- Text collection tool (e.g., Prodigy annotation platform)
- Domain experts (polymer scientists) for annotation
- Pre-defined ontology with entity definitions
- Inter-annotator agreement metrics (Cohen's Kappa, Fleiss Kappa)
Procedure:
- Corpus Compilation: Collect polymer-related abstracts or full-text paragraphs from scientific literature. Filter documents containing polymer-relevant terms (e.g., "poly") and numeric information likely to represent property values [20].
- Ontology Definition: Establish a clear ontology specifying entity types (Table 1) and annotation guidelines. The PolyNERE ontology provides a customizable starting point adaptable to specific research needs [21].
- Pre-annotation: Automatically pre-annotate texts using dictionaries of known entities where available to speed up the manual annotation process [20].
- Multi-round Annotation: Conduct annotation over multiple rounds (e.g., three rounds) with a small sample of abstracts in each round. Refine annotation guidelines between rounds and re-annotate previous abstracts using updated guidelines [20].
- Quality Assurance: Calculate inter-annotator agreement metrics using subset of abstracts annotated by all annotators. Target Fleiss Kappa values of approximately 0.885, comparable to benchmarks in the literature [20].
- Data Splitting: Split the annotated corpus into training (85%), validation (5%), and test (10%) sets for model development and evaluation [20].
NER Model Training Protocol
Objective: To train a specialized NER model for recognizing polymer-related entities in scientific text.
Materials and Tools:
- Annotated polymer corpus (e.g., PolymerAbstracts with 750 annotated abstracts)
- Computational resources (GPUs recommended)
- Deep learning frameworks (e.g., PyTorch, TensorFlow)
- Pre-trained language models (e.g., MaterialsBERT, PubMedBERT)
Procedure:
- Model Selection: Choose a pre-trained language model as the foundation. MaterialsBERT, trained on 2.4 million materials science abstracts, has demonstrated superior performance for polymer NER tasks [20] [9].
- Architecture Design: Implement a sequence labeling architecture where the BERT-based encoder generates contextual token embeddings, followed by a linear layer with softmax non-linearity to predict entity types [20].
- Hyperparameter Tuning: Set training parameters including dropout rate (e.g., 0.2), batch size, learning rate, and sequence length limit (e.g., 512 tokens, with truncation for longer sequences) [20].
- Model Training: Fine-tune the pre-trained model on the annotated polymer corpus using the cross-entropy loss function. Monitor performance on the validation set to prevent overfitting.
- Model Evaluation: Assess trained model performance on the held-out test set using standard NER metrics (precision, recall, F1-score). Compare against baseline models to verify performance improvements [20].
LLM-Based Extraction Protocol
Objective: To implement a large language model pipeline for extracting polymer-property data from full-text articles.
Materials and Tools:
- LLM access (GPT-3.5, LlaMa 2, or similar)
- Computational resources for LLM inference
- Two-step filtering system (heuristic and NER filters)
- Prompt engineering framework
Procedure:
- Corpus Processing: Divide full-text articles into individual paragraphs as processing units. For a corpus of 681,000 polymer-related articles, this typically results in approximately 23.3 million paragraphs [1].
- Heuristic Filtering: Apply property-specific heuristic filters to detect paragraphs mentioning target polymer properties or manually curated co-referents. This typically reduces the paragraph count to about 11% of the original (e.g., 2.6 million paragraphs from 23.3 million) [1].
- NER Filtering: Apply an additional NER filter to identify paragraphs containing all necessary named entities (material name, property name, property value, unit). This further refines the dataset to approximately 3% of original paragraphs (e.g., 716,000 from 23.3 million) [1].
- LLM Prompting: Design optimized prompts for the target LLM, incorporating in-context few-shot learning with task-specific examples. Carefully manage token limits to maximize efficiency [1].
- Structured Extraction: Use the LLM to extract property data in structured format, establishing relationships between materials and their properties.
- Cost Optimization: Monitor and optimize API calls or computational resources to manage extraction costs, particularly when processing large corpora [1].
Workflow Visualization
Polymer NER Workflow: From literature to structured data
The Researcher's Toolkit
Table 3: Essential Research Reagents and Computational Tools for Polymer NER
| Tool/Resource | Type | Function | Application Example |
|---|---|---|---|
| MaterialsBERT | Language Model | Domain-specific pre-trained model for materials science NER | Base encoder for polymer entity recognition [20] |
| PolyNERE Corpus | Annotated Dataset | 750 polymer abstracts with entity and relation annotations | Benchmark for model training and evaluation [21] |
| Prodigy | Annotation Tool | Active learning-based annotation platform for creating training data | Manual annotation of polymer entities in abstracts [20] |
| GPT-3.5/Turbo | Large Language Model | General-purpose LLM for few-shot/zero-shot extraction | Property data extraction from full-text paragraphs [1] |
| ChemDataExtractor | NLP Toolkit | Rule-based system for chemical data extraction | Baseline for polymer entity recognition [20] |
| Polymer Scholar | Database | Public repository of extracted polymer-property data | Validation and utilization of extracted data [1] |
Implementation Considerations
When implementing NER systems for polymer ontologies, several practical considerations emerge from recent research. The transition from processing abstracts to full-text paragraphs presents significant challenges, as full-text documents contain more complex language, dispersed information, and varied formatting [21]. Hybrid approaches that combine the precision of specialized NER models like MaterialsBERT with the flexibility of LLMs show promise for addressing these challenges [1].
Cost optimization remains critical, particularly when using commercial LLMs for large-scale extraction. The two-stage filtering system described in the protocols section reduces the number of paragraphs requiring LLM processing by approximately 97%, dramatically decreasing computational costs [1]. Furthermore, prompt engineering with few-shot learning examples significantly improves extraction accuracy without the need for extensive model fine-tuning [1].
Future developments in polymer NER will likely focus on improved relation extraction capabilities, better handling of polymer nomenclature variations, and more efficient integration of multi-modal data (e.g., connecting textual descriptions with chemical structures in figures) [1]. As these technologies mature, they will increasingly accelerate polymer discovery and design by making vast quantities of historical research accessible for computational analysis and machine learning.
The field of polymer informatics is fundamentally constrained by the fact that a vast amount of critical materials knowledge—encompassing synthesis conditions, measured properties, and performance metrics—exists locked within unstructured natural language text, such as scientific journal articles [14] [22]. Relation Extraction (RE), a specialized subfield of Natural Language Processing (NLP), aims to automate the transformation of this unstructured text into structured, machine-readable data by identifying and linking key entities. In the context of polymer science, this primarily involves connecting mentions of polymer materials to their properties and the associated numerical values and units [1]. This process is a critical enabling technology for building large-scale materials databases, which in turn power machine learning and data-driven discovery for advanced applications, including energy storage, sustainable polymers, and drug delivery systems [14].
The advent of Large Language Models (LLMs) has dramatically shifted the paradigm for RE, moving away from hand-tuned, rule-based systems and small, task-specific models towards more general, flexible, and powerful pipelines that can understand complex scientific context [22]. This document outlines the core principles, detailed protocols, and practical toolkit for implementing modern RE systems to connect polymer materials to their properties and performance characteristics.
Core Concepts and Relation Types
In polymer RE, the primary relationship of interest is the Material-Property-Value triple. This fundamental unit can be extended to include other crucial entities that provide context and enable more sophisticated data analysis. The table below summarizes the key entity and relation types targeted in a comprehensive polymer RE pipeline.
Table 1: Key Entity and Relation Types in Polymer Relation Extraction
| Entity Type | Description | Examples | Core Relation |
|---|---|---|---|
| Material | The polymer or material system being described. | "polyethylene", "PMMA", "PS-b-P2VP block copolymer" | Material -> has Property -> Value |
| Property | A measurable characteristic of the material. | "glass transition temperature", "tensile strength", "band gap" | |
| Value & Unit | The numerical quantity and its associated unit for the property. | "125", "MPa", "3.2 eV" | |
| Processing Parameter | A condition or variable from a manufacturing process. | "melt temperature", "injection pressure", "mold temperature" [3] | Material -> processed with -> Parameter -> Value |
| Performance Metric | A measure of the material's efficacy in an application. | "hydrogen storage capacity", "power conversion efficiency" | Material -> exhibits -> Performance -> Value |
Workflow and Experimental Protocol
A robust, large-scale RE pipeline involves a sequence of steps designed to efficiently process a large corpus of documents while maximizing accuracy and minimizing computational cost [1] [2]. The following protocol details a hybrid approach that leverages both traditional NLP methods and modern LLMs.
Protocol 1: Large-Scale Polymer-Property Data Extraction from Scientific Literature
Objective: To automatically extract structured polymer-property data from a large corpus (millions) of full-text journal articles [1].
Inputs: A corpus of scientific articles in PDF or structured XML/HTML format. For the study in [1], this involved ~2.4 million materials science articles.
Step-by-Step Procedure:
Corpus Assembly and Preprocessing:
- Collect journal articles from publisher APIs (e.g., Elsevier, Wiley, Springer Nature, ACS, RSC) using Crossref indexing and authorized downloads [1].
- Convert all documents to a consistent, machine-readable text format (e.g., XML, HTML). While PDF-to-text converters exist, structured formats are preferred for large-scale work [2].
- Segment the full text of each article into manageable units, such as individual paragraphs. This results in a large set of text segments (e.g., 23.3 million paragraphs from 681,000 polymer-related articles) [1].
Two-Stage Text Filtering:
- Heuristic Filtering: Pass each paragraph through property-specific keyword and regular expression filters to identify text relevant to the target properties (e.g., "glass transition", "Tg", "Young's modulus"). This drastically reduces the number of paragraphs for downstream processing (e.g., from 23.3M to ~2.6M) [1].
- NER Filtering: Apply a Named Entity Recognition model (e.g., MaterialsBERT) to the remaining paragraphs to confirm the presence of all necessary entities:
material,property,value, andunit. This step ensures that only paragraphs containing a complete, extractable data record are passed to the final, more expensive extraction step, further refining the dataset (e.g., to ~716,000 paragraphs) [1].
Core Relation Extraction:
- This can be performed using one of two model types:
- Option A (Specialized NER/RE Models): Use a domain-specific model like MaterialsBERT, which is pre-trained on materials science text, to perform joint named entity recognition and relation extraction. This is often more computationally efficient for large-scale runs [1].
- Option B (LLM-Based Agents): Use a large language model (e.g., GPT-3.5, GPT-4, LLaMA 2) as part of an agentic workflow [2]. The LLM is prompted with the filtered paragraph and a schema defining the required entities and relationships. Multi-agent systems can be employed, with different agents specializing in finding materials, extracting properties, and handling data from tables [2].
- This can be performed using one of two model types:
Post-Processing and Validation:
- Normalization: Convert all extracted values and units to a standard format (e.g., converting
MPatoGPa). - Domain Validation: Apply rule-based checks using domain knowledge to flag physically implausible values (e.g., a glass transition temperature of 10,000°C) [22].
- Structured Output: Compile the validated Material-Property-Value triples into a structured database (e.g., a CSV file or SQL database).
- Normalization: Convert all extracted values and units to a standard format (e.g., converting
Output: A structured database of polymer-property records. The application of this protocol in [1] resulted in a public database of over one million records for 24 different properties across 106,000 unique polymers, available via the Polymer Scholar website.
Protocol 2: Fine-Tuning an LLM for Specific Polymer Processing Extraction
Objective: To adapt a general-purpose, open-source LLM for high-accuracy extraction of complex polymer processing parameters, where terminology is highly context-dependent [3].
Inputs: A pre-trained LLM (e.g., LLaMA 2-7B); a small dataset of expert-annotated text samples containing processing parameters.
Step-by-Step Procedure:
Task and Schema Definition: Clearly define the entities and relations to be extracted. For injection molding, this includes parameters like
melt_temperature,mold_temperature,injection_pressure,holding_pressure, andcooling_time, and their relation to the mentioned polymer material [3].Data Collection and Annotation:
- Collect a relatively small set of text segments (e.g., 200-300 samples) from the scientific literature that describe the target processing method.
- Have domain experts annotate these samples, labeling the relevant entities and their relationships. This creates a gold-standard training and evaluation dataset.
Model Fine-Tuning:
- Use an efficient fine-tuning method like QLoRA (Quantized Low-Rank Adaptation). QLoRA dramatically reduces computational requirements by freezing the base model and only training a small number of added parameters, making it feasible on a single GPU [3].
- Fine-tune the LLM on the annotated dataset, framing the task as a text-to-text generation problem where the model learns to output the structured data (e.g., in JSON format) based on the input text.
Evaluation:
- Evaluate the fine-tuned model on a held-out test set of annotated examples.
- Report standard metrics such as accuracy, precision, recall, and F1-score for entity and relation extraction. The study in [3] achieved 91.1% accuracy and a 98.7% F1-score using this method with only 224 fine-tuning samples.
Performance Benchmarking
Selecting the appropriate model for a RE task requires balancing performance, cost, and computational requirements. The following table summarizes a comparative benchmark from the literature.
Table 2: Performance and Cost Benchmark of Models for Polymer Data Extraction
| Model / Approach | Best For | Reported Performance | Cost & Efficiency Considerations |
|---|---|---|---|
| Specialized NER (e.g., MaterialsBERT) | Large-scale processing of millions of documents; high-throughput screening [1]. | High performance on entity recognition; forms the backbone of large-scale pipelines [1]. | Lower computational cost for inference at scale compared to LLMs. Requires domain-specific pre-training/fine-tuning. |
| Proprietary LLM (e.g., GPT-4, GPT-3.5) | High accuracy tasks; complex relationship extraction; handling diverse writing styles with zero/few-shot learning [1] [2]. | GPT-4.1: F1 ~0.91 for thermoelectric properties [2]. GPT-3.5: Used to extract >1M polymer records [1]. | Higher monetary cost per API call. GPT-3.5 offers a favorable cost-quality trade-off for large-scale deployment [2]. |
| Open-Source LLM (e.g., LLaMA 2) | Scenarios requiring data privacy, custom fine-tuning, and reduced long-term cost [1] [3]. | Performance is competitive, especially after fine-tuning (e.g., 91.1% accuracy for processing parameters) [3]. | High initial computational cost for fine-tuning and hosting. Inference can be optimized (e.g., via quantization). |
| Agentic LLM Workflow | Complex extraction tasks requiring reasoning across different parts of a document (text, tables, captions) [2]. | High comprehensiveness and accuracy by leveraging multiple specialized agents and conditional logic [2]. | Increased complexity and potential for higher token consumption, which must be managed through intelligent routing [2]. |
This section lists the essential "research reagents"—software models, data, and tools—required to build and deploy a polymer relation extraction pipeline.
Table 3: Essential Toolkit for Polymer Relation Extraction Research
| Tool / Resource | Type | Function in the Pipeline | Examples / Notes |
|---|---|---|---|
| Pre-trained Language Models | Software | Provides the foundational NLP capability for understanding scientific text. | General LLMs: GPT-4, GPT-3.5, LLaMA 2, Gemini [1] [2]. Domain-Specific BERT: MaterialsBERT, MatBERT, ChemBERT [1] [22]. |
| Annotation Platform | Software | Enables the creation of labeled training and test data by domain experts. | LabelStudio, doccano, INCEpTION. Critical for fine-tuning and evaluation. |
| Structured Polymer Database | Data | Serves as a ground-truth source for training models and validating extraction results. | Polymer Scholar: Contains over 1M extracted property records [1]. |
| Fine-Tuning Framework | Software | Adapts a pre-trained model to a specific RE task with limited labeled data. | QLoRA: Efficient fine-tuning with reduced memory usage [3]. Hugging Face Transformers: Standard library for model training and inference. |
| Orchestration Framework | Software | Manages complex, multi-step agentic workflows for document processing. | LangGraph: Used to build stateful, multi-agent extraction pipelines with conditional logic [2]. |
| Corpus of Polymer Literature | Data | The primary source input from which data is extracted. | Can be built using publisher APIs (Elsevier, RSC, Springer) and text extraction tools from PDF/XML [1] [2]. |
Application Notes: NLP for Polymer Electrolyte Fuel Cell (PEFC) Development
Background and Significance
Polymer Electrolyte Fuel Cells (PEFCs) represent a critical clean energy technology for transportation and stationary power applications. Recent advances have focused on considerable improvements in design, materials, economy of scale, efficiency, and cost-effectiveness [23]. International research initiatives like Task 31 are specifically aimed at reducing costs and improving the performance of PEFCs and direct methanol fuel cells (DMFCs) through advanced materials development and system optimization [24]. The development of durable, cost-effective materials including polymer electrolyte membranes, electrode catalysts, and membrane-electrode assemblies remains a primary research focus.
Quantitative Performance Data of PEFC Components
Table 1: Key Polymer Components and Properties in PEFC Applications
| Component Type | Key Properties | Target Performance Metrics | Data Source |
|---|---|---|---|
| Polymer Electrolyte Membranes | Proton conductivity, Chemical stability, Mechanical strength | >0.1 S/cm proton conductivity; >5000 hours operational lifetime | [24] |
| Electrode Catalysts | Activity, Durability, Poisoning resistance | Reduced platinum loading; Enhanced CO tolerance | [24] |
| Bipolar Plates | Electrical conductivity, Corrosion resistance | <0.02 Ω·cm² contact resistance; >10,000 h lifespan | [24] |
| Membrane-Electrode Assemblies | Power density, Operational lifetime | >1 W/cm² peak power density; <10% voltage degradation over 5000h | [23] [24] |
NLP Data Extraction Protocol for PEFC Literature
Objective: Extract structured polymer property data from PEFC scientific literature using Large Language Models.
Materials and Computational Resources:
- GPT-3.5 or LlaMa 2 LLMs
- MaterialsBERT NER model
- Corpus of polymer-related scientific articles (e.g., 681,000 documents from Polymer Scholar database)
- Computational infrastructure with adequate GPU resources
Methodology:
- Corpus Preprocessing: Identify polymer-related documents from a materials science corpus of ~2.4 million articles by searching for term 'poly' in titles and abstracts [1].
- Paragraph Segmentation: Process full-text articles into individual text units (~23.3 million paragraphs from 681,000 polymer-related documents).
- Two-Stage Filtering:
- Heuristic Filter: Apply property-specific filters to detect paragraphs mentioning target PEFC polymer properties (e.g., proton conductivity, membrane stability).
- NER Filter: Use MaterialsBERT to identify paragraphs containing complete entity sets (material name, property name, property value, unit).
- LLM-Powered Data Extraction: Process filtered paragraphs through GPT-3.5 with few-shot learning prompts to extract structured polymer-property relationships.
- Data Validation: Implement cross-verification between LLM and NER model outputs to ensure data quality.
Expected Outcomes: Extraction of over one million records corresponding to 24 properties of over 106,000 unique polymers, with specific focus on PEFC-relevant polymer electrolytes and components [1].
Diagram 1: NLP workflow for polymer data extraction from fuel cell literature.
Application Notes: NLP for Perovskite Solar Cell Innovation
Background and Significance
Solar panel technology is undergoing rapid, disruptive evolution, with perovskite solar cells emerging as particularly promising due to their low production costs and high efficiency potential [25]. Recent breakthroughs include perovskite-silicon tandem solar cells achieving record efficiencies of 31-32% under standard test conditions, significantly surpassing conventional crystalline silicon PVs which plateau at approximately 26% [26]. These advancements are especially relevant for transportation applications, including Vehicle-Integrated PVs (VIPVs) that provide cleaner energy alternatives for automotive, aerospace, and marine platforms [26].
Quantitative Performance Data of Advanced Solar Cells
Table 2: Performance Metrics of Advanced Solar Cell Technologies (2022-2025)
| Solar Cell Technology | Power Conversion Efficiency | Key Advantages | Stability Challenges |
|---|---|---|---|
| Perovskite-Silicon Tandem | 31-32% (lab); >30% (reproducible) | Bandgap tunability; Thinner, lighter active layers | Degradation under thermal cycling, vibration, UV exposure [26] |
| Heterojunction (HJT) | >26% (commercial) | Improved low-light performance; Longer lifespan | - |
| Flexible & Lightweight | 18x more power per kg vs conventional | Conformal installation on curved vehicle surfaces | Mechanical stress; Environmental protection [25] |
| Quantum Dot | Potential for 30%+ | Customizable solar absorption; Lower environmental impact | - |
NLP Data Extraction Protocol for Polymer-Based Solar Cells
Objective: Automate extraction of polymer and perovskite photovoltaic property data from scientific literature.
Materials and Computational Resources:
- Transformer-based LLMs (GPT series, LlaMa 2)
- Domain-specific fine-tuned models (MaterialsBERT)
- Solar energy research corpus with annotated polymer photovoltaic properties
- High-performance computing cluster for processing large text volumes
Methodology:
- Domain-Specific Corpus Development: Assemble specialized corpus of perovskite and polymer solar cell literature through publisher APIs (Elsevier, Wiley, Springer Nature, ACS, RSC).
- Property-Targeted Filtering: Implement focused heuristic filters for photovoltaic properties including:
- Bandgap values and tunability
- Thermal and photochemical stability metrics
- Efficiency measurements under standard test conditions
- Encapsulation performance data
- Relationship Extraction: Employ LLM few-shot learning with carefully crafted prompts to identify polymer-perovskite composite relationships and performance characteristics.
- Structured Data Organization: Output structured records linking polymer compositions to operational stability data critical for transportation applications.
- Cross-Validation: Implement human expert validation on extracted data subsets to quantify extraction accuracy and reliability.
Expected Outcomes: Comprehensive database of structure-property relationships for polymer-encapsulated perovskites, enabling machine learning predictions of optimal formulations for specific transportation operating conditions [1] [8].
Research Reagent Solutions for Solar Cell Development
Table 3: Essential Materials for Advanced Solar Cell Research
| Research Reagent | Function | Application Specifics |
|---|---|---|
| Perovskite Precursors (e.g., PbI₂, FAI) | Light-absorbing active layer | Form perovskite crystal structure with tunable bandgap [25] |
| Charge Transport Polymers (e.g., PEDOT:PSS, Spiro-OMeTAD) | Hole/electron transport layers | Facilitate charge extraction while minimizing recombination [25] |
| Encapsulation Polymers (e.g., UV-stabilized fluoropolymers) | Environmental protection | Barrier against moisture ingress and UV degradation [26] |
| Flexible Substrates (e.g., Polyimide, PET) | Support for lightweight cells | Enable conformal installation on curved surfaces [25] |
Diagram 2: NLP pipeline for extracting solar cell stability data for transport.
Application Notes: NLP for Advanced Drug Delivery Systems
Background and Significance
The pharmaceutical industry is experiencing unprecedented innovation in drug delivery technologies, with pharmaceutical manufacturers adopting advanced delivery platforms to improve drug efficacy and patient compliance [27]. Despite thousands of published nanomedicines in preclinical trials, only an estimated 50-80 nanomedicines had achieved global approval for clinical use by 2025, highlighting a significant translational gap between laboratory research and clinical applications [28]. This gap is particularly pronounced for polymer-based delivery systems, where formulation strategies must address both biological barriers and manufacturing challenges.
Quantitative Performance Data of Drug Delivery Systems
Table 4: Advanced Formulation Platforms for Polymer-Based Drug Delivery
| Formulation Platform | Key Characteristics | Administration Route | Clinical Translation Status |
|---|---|---|---|
| Lipid Nanoparticles (LNPs) | Versatile encapsulation; PEGylatable | Intravenous, intramuscular | High (proven by COVID-19 mRNA vaccines) [28] |
| Polymer-Based Nanoparticles (e.g., PLGA) | Controlled release profiles; Biodegradable | Various, including sustained release | Moderate (several clinical approvals) [28] |
| Long-Acting Injectables | Weeks or months duration | Subcutaneous, intramuscular | Growing adoption for chronic conditions [27] |
| Microneedle Patches | Painless transdermal delivery | Transdermal | Emerging (preclinical/early clinical) [27] |
NLP Data Extraction Protocol for Polymer Drug Delivery Systems
Objective: Extract and structure polymer formulation data from pharmaceutical literature to bridge the translational gap in nanomedicine.
Materials and Computational Resources:
- Fine-tuned GPT models on pharmaceutical literature
- Specialized NER models for biomedical texts
- Annotated corpus of drug delivery research papers and patents
- Cloud computing infrastructure for processing large datasets
Methodology:
- Comprehensive Corpus Assembly: Collect full-text articles focusing on polymer-based drug delivery systems from major pharmaceutical and materials science publishers.
- Multi-Scale Entity Recognition:
- Core particle design parameters (materials, synthesis methods)
- Surface engineering features (PEGylation, targeting ligands)
- Final dosage form characteristics (sterile injectables, implants, topical formulations)
- Translational Gap Analysis: Implement specialized filters to identify paragraphs discussing specific translational challenges:
- Scale-up manufacturing issues
- Batch-to-batch variability reports
- Stability and storage challenges
- Regulatory consideration discussions
- Dosage-Property Relationship Extraction: Use chain-of-thought prompting with LLMs to extract complex relationships between polymer properties and in vivo performance.
- Structured Knowledge Graph Construction: Output interconnected data linking polymer chemical structures to formulation strategies, performance metrics, and translational hurdles.
Expected Outcomes: Structured database identifying critical formulation parameters that correlate with successful clinical translation, enabling data-driven decision making in polymer-based drug delivery system development [1] [28].
Research Reagent Solutions for Drug Delivery Development
Table 5: Essential Materials for Advanced Drug Delivery Research
| Research Reagent | Function | Formulation Considerations |
|---|---|---|
| Biodegradable Polymers (e.g., PLGA) | Controlled release matrix | Molecular weight, copolymer ratio, degradation rate [28] |
| PEG-Based Lipids | Stealth coating for nanoparticles | PEG chain length, density, alternatives to address immunogenicity [28] |
| Targeting Ligands (e.g., peptides, antibodies) | Active targeting to specific tissues | Ligand density, orientation, stability during circulation [28] |
| Stimuli-Responsive Polymers (e.g., pH-sensitive) | Environment-responsive drug release | Trigger specificity, response kinetics, biocompatibility [27] |
Diagram 3: NLP workflow for analyzing drug delivery translation gaps.
PolymerScholar.org, also known as Polymer Scholar, is an online platform designed to accelerate polymer research by providing access to a vast repository of automatically extracted polymer-property data. Its primary function is to enable researchers to search millions of polymer property records obtained from the full-text journal articles using advanced Natural Language Processing (NLP) techniques, including large language models (LLMs) like GPT-3.5 and the specialized MaterialsBERT named entity recognition model [29]. This tool addresses a critical need in materials informatics: transforming unstructured data from scientific literature into a structured, searchable format to advance data-driven materials discovery [1].
Platform Capabilities and Data Extraction Methodology
Data Extraction Pipeline
The foundational technology behind PolymerScholar involves a sophisticated NLP pipeline for automated data extraction from polymer science literature. The process, as detailed in Communications Materials, involves several key stages [1]:
- Corpus Processing: The pipeline begins with a massive corpus of approximately 2.4 million materials science journal articles published over two decades. From these, around 681,000 polymer-related documents are identified.
- Text Unit Segmentation: Individual paragraphs from these articles are treated as distinct text units, resulting in 23.3 million paragraphs for processing.
- Two-Stage Filtering:
- Heuristic Filter: Paragraphs are passed through property-specific heuristic filters designed to detect mentions of target polymer properties or their co-referents. This stage identifies about 2.6 million relevant paragraphs (~11% of the total).
- NER Filter: A Named Entity Recognition (NER) filter then identifies paragraphs containing all necessary entities—material name, property name, property value, and unit—confirming the existence of a complete, extractable record. This refines the dataset to about 716,000 paragraphs (~3%).
- Structured Data Extraction: The filtered paragraphs are processed using either MaterialsBERT or GPT-3.5 to identify materials and properties, establish relationships, and extract the information into a structured format.
This pipeline has successfully extracted over one million records corresponding to 24 key properties of more than 106,000 unique polymers [1].
Interactive Data Exploration
PolymerScholar provides four primary modes for exploring the extracted data [30]:
- Polymer Name Input: Returns a bar chart of the most commonly reported properties for the specified polymer.
- Polymer and Property Name Input: Generates an interactive plot of property values along with a value histogram.
- Single Property Name Input: Displays an interactive plot of all values for that property across the database.
- Two Property Names Input: Creates an interactive pairwise plot (property B vs. property A) for correlation analysis.
Users can filter results to show data extracted specifically by the GPT-3.5 or MaterialsBERT pipelines, allowing for comparative analysis [30].
The following tables summarize the scale and scope of data available through PolymerScholar.org and the properties targeted for extraction.
Table 1: Scale of Data in PolymerScholar.org
| Metric | Value | Source |
|---|---|---|
| Total Journal Articles Processed | ~2.4 million | [1] |
| Polymer-Related Articles Identified | ~681,000 | [1] |
| Total Paragraphs Processed | 23.3 million | [1] |
| Unique Polymers with Extracted Data | >106,000 | [1] |
| Total Property Records Extracted | >1 million | [1] |
Table 2: Targeted Polymer Properties for Extraction
| Category | Example Properties |
|---|---|
| Thermal Properties | Glass Transition Temperature (Tg) [1] |
| Optical Properties | Bandgap, Refractive Index [1] |
| Transport Properties | Gas Permeability [1] |
| Mechanical Properties | Tensile Strength, Modulus [1] |
Experimental Protocols for Polymer Data Extraction
Protocol: LLM-Driven Data Extraction from Polymer Literature
This protocol outlines the methodology for using large language models to extract structured polymer-property data from scientific text, as implemented in PolymerScholar [1].
Primary Research Reagent Solutions:
- Text Corpus: A collection of ~2.4 million full-text journal articles from publishers including Elsevier, Wiley, Springer Nature, American Chemical Society, and the Royal Society of Chemistry [1].
- LLM for Extraction: GPT-3.5 (OpenAI) or Llama 2 (Meta), used for their advanced text comprehension and generation capabilities [1].
- Specialized NER Model: MaterialsBERT, a transformer-based model fine-tuned on materials science text for identifying key entities [1].
- Computing Infrastructure: Significant computational resources, including cloud computing and tensor processing units (TPUs), required for LLM inference [1].
Procedure:
- Corpus Assembly and Polymer Identification: Gather the full-text article corpus. Identify polymer-related documents by searching for the term 'poly' in titles and abstracts [1].
- Text Segmentation: Divide each article into individual paragraphs, treating each as an independent text unit for processing [1].
- Heuristic Filtering: Pass each paragraph through property-specific heuristic filters. These are manually curated rules that detect the presence of target polymer properties or related terms [1].
- NER Filtering: Process the heuristic-filtered paragraphs with the MaterialsBERT model to verify the presence of all required named entities:
material,property,value, andunit. Discard paragraphs missing any entity [1]. - LLM Prompting and Data Extraction: Feed the filtered paragraphs to the LLM (e.g., GPT-3.5) using a carefully designed prompt. Utilize few-shot learning (providing a few annotated examples within the prompt) to guide the model in extracting data into a structured format (e.g., JSON) [1].
- Data Validation and Storage: Implement validation checks, potentially using domain knowledge or physical laws, to assess the plausibility of extracted data. Store validated records in the PolymerScholar database [1].
Troubleshooting and Optimization:
- Cost Management: LLM inference incurs significant monetary costs. Optimize by using the two-stage filtering to minimize the number of paragraphs sent to the LLM [1].
- Performance Tuning: Experiment with different few-shot example sets and prompt phrasing (prompt engineering) to improve extraction accuracy [1].
Protocol: Fine-Tuning an LLM for specialized Polymer Data Extraction
This protocol describes a fine-tuning approach, as demonstrated for extracting polymer processing parameters, which can be adapted for other specialized polymer properties [3].
Primary Research Reagent Solutions:
- Base LLM: A pre-trained open-source model like Llama-2-7B-Chat [3].
- Fine-Tuning Framework: QLoRA (Quantized Low-Rank Adaptation) for efficient parameter fine-tuning with minimal computational overhead [3].
- Annotation Dataset: A limited set (e.g., 224 samples) of expert-annotated text passages containing the target information [3].
Procedure:
- Task and Data Definition: Define the specific entities and relationships to extract (e.g., for processing parameters: polymer, processing method, temperature, pressure). Manually annotate a small corpus of text to create gold-standard examples [3].
- Context Compression (Optional): Use similarity search or regular expressions to identify and extract the most relevant paragraphs from full-text articles before processing, to fit the model's input length constraints [3].
- Prompt Engineering: Design a detailed instruction prompt that clearly defines the extraction task, the required output format, and the entities of interest [3].
- Model Fine-Tuning: Apply the QLoRA method to fine-tune the base Llama-2 model on the annotated dataset. This adapts the model's weights to the specific domain task without requiring full retraining [3].
- Structured Output Parsing: Implement a parser to convert the model's text-based output (e.g., a JSON string) into a structured data record [3].
- Evaluation: Assess the model's performance on a held-out test set using metrics such as accuracy and F1-score, which reached 91.1% and 98.7% respectively in the referenced study [3].
Workflow Visualization
PolymerScholar.org represents a significant advancement in the application of NLP and LLMs for polymer informatics. By providing a publicly accessible platform built on a robust, scalable data extraction pipeline, it enables researchers to navigate the vast landscape of polymer literature with unprecedented efficiency. The detailed protocols for both direct LLM extraction and fine-tuning provide a roadmap for researchers to adapt these powerful techniques to their specific data extraction challenges. As LLM technology continues to evolve, platforms like PolymerScholar are poised to become indispensable tools in the accelerating discovery and development of new polymeric materials.
Overcoming Implementation Hurdles: Data Quality, Model Accuracy, and Interpretation
Addressing Data Scarcity and Quality Issues in Polymer Literature
The field of polymer informatics faces a significant challenge due to the scarcity of high-quality, structured data, as the vast majority of polymer knowledge remains locked within unstructured scientific literature [8]. The exponential growth of publications makes manual curation infeasible, creating a critical bottleneck for data-driven materials discovery [9]. Natural Language Processing (NLP) and Large Language Models (LLMs) have emerged as transformative technologies to automate the extraction of structured polymer-property data from scientific texts at scale [1] [8]. This application note details practical protocols and solutions for implementing these technologies to overcome data scarcity and quality issues in polymer science.
Experimental Protocols for Polymer Data Extraction
Corpus Assembly and Pre-processing
Objective: To assemble a comprehensive corpus of polymer literature for downstream NLP processing.
Materials:
- Crossref Database: For initial article indexing and metadata collection.
- Publisher APIs: Authorized access to full-text content from major publishers (Elsevier, Wiley, Springer Nature, American Chemical Society, Royal Society of Chemistry).
- Computing Infrastructure: High-performance computing cluster with adequate storage for processing millions of documents.
Procedure:
- Initial Retrieval: Index approximately 2.4 million materials science journal articles published over the last two decades through Crossref [1].
- Full-text Acquisition: Download authorized full-text content from 11 major publishers using institutional subscriptions and API access.
- Polymer-focused Filtering: Identify polymer-relevant documents (~681,000) by searching for the term 'poly' in titles and abstracts [1].
- Text Unit Segmentation: Process individual paragraphs as discrete text units, resulting in approximately 23.3 million paragraphs from polymer-related documents.
- Format Standardization: Convert all documents to a consistent plain text format, preserving paragraph structure but removing formatting elements.
Two-Stage Text Filtering Protocol
Objective: To efficiently identify paragraphs containing extractable polymer-property data while minimizing computational costs.
Table 1: Target Polymer Properties for Extraction
| Property Category | Specific Properties | Application Relevance |
|---|---|---|
| Thermal Properties | Glass transition temperature, Melting point | Polymer processing, stability |
| Optical Properties | Refractive index, Bandgap | Dielectric aging, breakdown |
| Transport Properties | Gas permeability | Filtration, distillation |
| Mechanical Properties | Tensile strength, Elastic modulus | Thermosets, recyclable polymers |
Procedure:
- Heuristic Filtering:
- Develop property-specific keyword lists and regular expressions for 24 target polymer properties through manual literature review [1].
- Apply these filters to all 23.3 million paragraphs to identify approximately 2.6 million paragraphs (~11%) containing property-relevant language.
- Example keyword sets include: "glass transition", "Tg" for glass transition temperature; "refractive index", "nD" for refractive index.
- Named Entity Recognition (NER) Filtering:
- Apply a pre-trained MaterialsBERT NER model to identify paragraphs containing all necessary entities: material name, property name, property value, and unit [1] [9].
- This refined filtering yields approximately 716,000 paragraphs (~3%) containing complete, extractable property records.
- Validate entity recognition accuracy on a subset of 1000 manually annotated paragraphs.
LLM-Based Data Extraction Protocol
Objective: To extract structured polymer-property records from filtered paragraphs using large language models.
Materials:
- LLM Access: GPT-3.5 API access (commercial) or LlaMa 2 (open-source) installation [1].
- Prompt Templates: Pre-designed prompts for property extraction.
- Computing Resources: GPU cluster for running open-source models.
Procedure:
- Prompt Design:
- Develop specialized prompts for each of the 24 target properties with clear instructions for structured output.
- Implement few-shot learning with 3-5 representative examples per property to enhance extraction accuracy [1].
Batch Processing:
- Process filtered paragraphs through the LLM using appropriate batching strategies to optimize throughput.
- For GPT-3.5, utilize API batch processing features; for LlaMa 2, implement parallel inference on GPU clusters.
Structured Output Generation:
- Format LLM outputs as structured JSON records containing: polymer name, property, value, units, and source paragraph ID.
- Implement consistency checks to validate numerical ranges and unit conversions.
Data Validation:
- Conduct manual validation on a random subset of 500 extracted records per property.
- Calculate precision, recall, and F1 scores for each property category.
- Implement cross-verification between multiple models where feasible.
NER-Based Data Extraction Protocol
Objective: To extract polymer-property data using specialized NER models as an alternative to LLMs.
Materials:
- MaterialsBERT Model: Pre-trained transformer model specialized for materials science [9].
- Annotation Tools: Prodigy annotation platform for creating training data.
- Computing Infrastructure: GPU-enabled workstations for model training and inference.
Procedure:
- Model Training:
- Annotate 750 polymer abstracts using a specialized ontology with 8 entity types: POLYMER, POLYMERCLASS, PROPERTYVALUE, PROPERTYNAME, MONOMER, ORGANICMATERIAL, INORGANICMATERIAL, and MATERIALAMOUNT [9].
- Split annotated data into training (85%), validation (5%), and test (10%) sets.
- Fine-tune MaterialsBERT using the annotated dataset with a linear classification layer and dropout probability of 0.2.
Entity Recognition:
- Process all filtered paragraphs through the trained NER model.
- Apply BIO (Beginning-Inside-Outside) tagging to identify entity boundaries.
Relation Extraction:
- Implement rule-based algorithms to establish relationships between extracted entities.
- Use dependency parsing to identify syntactic relationships between material and property entities.
Structured Record Generation:
- Combine related entities into complete polymer-property records.
- Export structured data in standardized format for database ingestion.
Workflow Visualization
Diagram 1: Polymer Data Extraction Workflow from Literature
Performance Evaluation and Data Output
Model Performance Comparison
Table 2: Performance Metrics for Data Extraction Methods
| Model/Approach | Extraction Quantity | Quality (Precision) | Computational Cost | Time Efficiency | Best Use Cases |
|---|---|---|---|---|---|
| GPT-3.5 | High (~1M+ records) | High with few-shot learning | Significant monetary cost | Moderate (API dependent) | High-value extraction with budget |
| LlaMa 2 (Open-source) | High | Moderate to high | High hardware investment | Slower (local inference) | Data-sensitive applications |
| MaterialsBERT (NER) | ~300K from abstracts | High on trained entities | Lower after initial training | Fast once trained | Targeted property extraction |
| Hybrid Approach | Maximum coverage | Optimized through validation | Moderate to high | Variable | Production-scale pipelines |
Extracted Data Characteristics
Table 3: Polymer Data Extraction Outcomes
| Metric | Abstract-Only Extraction | Full-Text Extraction | Improvement |
|---|---|---|---|
| Unique Polymers | ~50,000 | 106,000+ | 112% increase |
| Property Records | ~300,000 | 1,000,000+ | 233% increase |
| Properties Covered | 15 | 24 | 60% increase |
| Data Sources | 130,000 abstracts | 681,000 full-text articles | 424% increase |
Research Reagent Solutions
Table 4: Essential Tools for Polymer Data Extraction Research
| Tool/Resource | Type | Function | Access |
|---|---|---|---|
| MaterialsBERT | NER Model | Polymer and property entity recognition | Open-source [9] |
| GPT-3.5 Turbo | LLM API | High-accuracy relation extraction | Commercial API |
| LlaMa 2 70B | LLM | Open-source alternative for data extraction | Open-weight |
| Polymer Scholar | Database | Repository for extracted polymer data | Public access [1] |
| OpenPoly Database | Benchmark Data | Curated experimental data for validation | Public access [31] |
| Prodigy | Annotation Tool | Manual annotation of training data | Commercial license |
| ChemDataExtractor | NLP Pipeline | Chemistry-aware text processing | Open-source |
Implementation Considerations
Cost Optimization Strategies
- Implement stringent paragraph filtering before LLM processing to reduce token usage [1]
- Use smaller, specialized models for initial processing stages
- Combine commercial and open-source models in a tiered approach based on task complexity
- Implement caching mechanisms for frequently processed text patterns
Quality Assurance Protocols
- Establish manual validation sets for each property category (minimum 100 records per property)
- Implement cross-model verification where multiple approaches extract the same data
- Develop polymer name normalization procedures to handle synonyms and abbreviations
- Create data quality metrics tracking accuracy, completeness, and consistency over time
Data Accessibility and Integration
The extracted polymer-property data is made publicly available through the Polymer Scholar website (polymerscholar.org), enabling researchers to explore property distributions and relationships [1] [9]. For benchmarking and model training, the OpenPoly database provides additional curated experimental data under Creative Commons Attribution 4.0 International license [31]. Integration with existing materials informatics platforms enables direct utilization of extracted data for machine learning and predictive modeling applications.
Optimizing Named Entity Recognition with Limited Annotated Data
Named Entity Recognition (NER) is a fundamental Natural Language Processing (NLP) technique that identifies and classifies key information entities—such as person names, locations, and organizations—within unstructured text, turning it into structured data [32]. For researchers in polymer science and drug development, the ability to automatically extract material property data from vast scientific literature is invaluable for inferring chemistry-structure-property relationships and accelerating discovery [9]. However, a significant bottleneck exists: obtaining high-quality, manually annotated data required to train supervised NER models is time-consuming, expensive, and demands domain expertise [9] [33] [34]. This challenge is particularly acute in specialized fields like polymer research, where domain-specific entities (e.g., POLYMER, PROPERTY_VALUE, MONOMER) are not recognized by general-purpose models [9].
This Application Note addresses the critical challenge of performing accurate NER in low-resource scenarios. We present and detail two proven, synergistic strategies: LLM-assisted data augmentation to artificially expand training datasets [35] [34], and parameter-efficient instruction tuning of Large Language Models (LLMs) to adapt powerful models to specialized domains with minimal computational overhead [36]. The protocols herein are framed within polymer data extraction research, providing scientists with practical methodologies to build robust NER systems without the need for massive annotated corpora.
Data Augmentation Strategies for NER
Data Augmentation (DA) generates new training examples from existing annotated data, increasing dataset size and diversity, which is crucial for improving model generalization in few-shot settings [34].
LLM-Assisted Contextual Paraphrasing
This technique uses a powerful LLM to rephrase sentences while preserving the original entity types and semantic meaning.
- Workflow: The process involves creating a masked template from the original sentence, where entities are replaced with type-specific placeholders (e.g.,
<POLYMER>,<PROPERTY_VALUE>). This template is then fed to an LLM with instructions to generate fluent paraphrases that maintain these placeholders [35]. - Protocol:
- Input Preparation: For a labeled sentence, replace each entity span with a corresponding semantic placeholder (e.g., "The glass transition of PMMA was measured at 115 °C" becomes "The glass transition of
<POLYMER>was measured at<PROPERTY_VALUE>"). - Prompt Design: Use a carefully engineered prompt, such as: "You are a helpful assistant. Generate a paraphrase of the following sentence while keeping all the XML-like tags (e.g.,
<POLYMER>) exactly as they are. Ensure the grammatical correctness and naturalness of the output. Original sentence: [Masked_Sentence]" [35]. - Generation: Query a capable LLM (e.g., LLAMA 3.3-70B [35] or ChatGPT [34]) multiple times with the same prompt to generate several paraphrased variants.
- Quality Control & Validation: Implement a validation pipeline to ensure generated paraphrases meet quality standards [35]:
- The number and type of entity tags must match the original.
- The semantic meaning must be preserved (validated via cosine similarity of sentence embeddings).
- The output must be grammatically correct and fluent.
- Dataset Expansion: Add the successfully validated paraphrases and their corresponding original entity mappings to the training set.
- Input Preparation: For a labeled sentence, replace each entity span with a corresponding semantic placeholder (e.g., "The glass transition of PMMA was measured at 115 °C" becomes "The glass transition of
The following diagram illustrates the LLM-assisted contextual paraphrasing workflow.
Quantitative Performance of Data Augmentation Techniques
The table below summarizes the performance improvements achieved by various data augmentation techniques as reported in recent literature.
Table 1: Impact of Data Augmentation on Few-Shot NER Performance
| Augmentation Technique | Domain | Model | Dataset | Performance Gain (F1 Score) | Citation |
|---|---|---|---|---|---|
| LLM-assisted Paraphrasing | General NER | Instruction-tuned LLMs (Qwen, LLAMA) | CrossNER | Improvement of up to 17 points over baseline | [35] |
| LLM-assisted Paraphrasing (ChatGPT) | Biomedical NER | PubMedBERT + Multi-scale feature extraction | BC5CDR-Disease (5-shot) | 10.2% increase over previous SOTA | [34] |
| LLM-assisted Paraphrasing (ChatGPT) | Biomedical NER | PubMedBERT + Multi-scale feature extraction | BC5CDR-Disease (50-shot) | 15.2% increase over previous SOTA | [34] |
| Cross-Lingual Augmentation | Low-Resource Languages (e.g., Pashto) | Fine-tuned multilingual LLMs | - | Significant improvements demonstrated | [37] |
Model Optimization with Limited Data
With augmented data, the next step is to select and fine-tune a model architecture efficiently.
Parameter-Efficient Instruction Tuning
Full fine-tuning of LLMs is computationally prohibitive. Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA (Low-Rank Adaptation) and QLoRA, dramatically reduce the number of trainable parameters by injecting and optimizing low-rank matrices into the model's layers, instead of updating all weights [36].
- Protocol: QLoRA Fine-tuning for Bio/NER Tasks [36]
- Model Selection: Choose a base open-source LLM (e.g., Llama 3.1-8B [35] or a domain-specific model).
- Quantization: Convert the pre-trained model's weights to a lower precision (e.g., 4-bit) to reduce memory footprint.
- Instruction Tuning: Formulate the NER task using an instruction template. This combines the input text, definitions of entity types, and a specification of the output format.
- QLoRA Configuration:
- Freeze the base quantized model.
- Introduce LoRA adapters with a specified rank (e.g., r=64). The
lora_alphaparameter scales the adapter outputs. - Apply these adapters to the attention mechanism's query, key, value, and output projections in the transformer layers.
- Training: Train only the LoRA adapter parameters on the (augmented) instruction-formatted NER dataset. This can be accomplished on a single GPU with 16GB of memory [36].
Instruction Template Design
The design of the instruction prompt is critical for guiding the LLM. An effective template should include [35]:
- Task Definition: A clear instruction to perform NER.
- Annotation Guidelines: Definitions and examples for each entity type.
- Negative Guidance: Explicit instruction on what not to tag.
- Output Format: A simple, structured format like word/tag pairs (e.g.,
PMMA/POLYMER transition/PROPERTY_NAME) to reduce model confusion [35].
Experimental Protocol: End-to-End Low-Resource NER
This integrated protocol combines data augmentation and efficient model tuning for polymer NER.
The following diagram outlines the complete experimental workflow for optimizing NER with limited annotated data.
Step-by-Step Procedure
Data Preparation and Augmentation
- Curate Seed Data: Assemble a small set of polymer abstracts (e.g., 50-200) annotated with a domain-specific ontology (e.g.,
POLYMER,PROPERTY_NAME,PROPERTY_VALUE,MONOMER) [9]. - Apply Augmentation: Follow the LLM-assisted paraphrasing protocol (Section 2.1) to expand your training set 3-5x. Two paraphrases per original sentence is a good starting point [35].
- Curate Seed Data: Assemble a small set of polymer abstracts (e.g., 50-200) annotated with a domain-specific ontology (e.g.,
Model Training with QLoRA
- Format Data: Apply the instruction template to every sentence in the augmented training set.
- Configure QLoRA:
- Base Model:
Llama-3.1-8B-Instruct - Quantization: 4-bit NormalFloat (NF4)
- LoRA Rank (r): 64
- LoRA Alpha: 16
- Target Modules:
q_proj,k_proj,v_proj,o_proj - Training Batch Size: Adjust based on GPU memory (start with 1-4).
- Base Model:
- Train: Execute training, monitoring loss on a held-out validation set.
Evaluation and Analysis
- Metrics: Evaluate the model on a held-out, non-augmented test set using standard metrics calculated for each entity type and for the model overall [38]:
- Precision:
True_Positive / (True_Positive + False_Positive) - Recall:
True_Positive / (True_Positive + False_Negative) - F1 Score:
2 * Precision * Recall / (Precision + Recall)
- Precision:
- Error Analysis: Use a Confusion Matrix to identify which entity types are frequently confused (e.g.,
POLYMERvs.ORGANIC_MATERIAL) and prioritize adding more targeted training examples for those classes [38].
- Metrics: Evaluate the model on a held-out, non-augmented test set using standard metrics calculated for each entity type and for the model overall [38]:
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Tools for Low-Resource NER in Scientific Domains
| Tool / Resource | Type | Primary Function in NER Pipeline | Relevant Citation |
|---|---|---|---|
| LLAMA 3.3-70B / ChatGPT | Large Language Model | Serves as the engine for high-quality, contextual data augmentation via paraphrasing. | [35] [34] |
| LoRA / QLoRA | Fine-tuning Method | Enables resource-efficient adaptation of large LLMs to specialized NER tasks by drastically reducing trainable parameters. | [36] |
| PubMedBERT / MaterialsBERT | Domain-Specific Language Model | Provides a pre-trained base model with embedded knowledge from scientific corpora, offering a superior starting point for biomedical/materials NER compared to general models. | [9] [36] |
| Instructor Library | Python Utility | Facilitates structured output generation from LLMs (e.g., JSON), crucial for validating and parsing augmented data. | [35] |
| Prodigy | Data Annotation Tool | An ecosystem for efficiently creating and refining labeled datasets, which is essential for building the initial seed data. | [9] |
The application of natural language processing (NLP) to polymer science presents a unique set of challenges that stem from the inherent complexity of polymeric materials. This complexity is twofold: firstly, polymers exhibit hierarchical structures across multiple spatial and temporal scales, from molecular interactions to macroscopic properties. Secondly, the field employs a heterogeneous mix of naming conventions, including systematic, source-based, trade, and common names, leading to significant inconsistencies in scientific literature. For NLP systems designed to extract and structure polymer data, these variations represent a major impediment to accurate information retrieval and integration. This document outlines the core challenges and provides detailed application notes and protocols for handling polymer complexity within NLP pipelines, specifically designed for researchers, scientists, and drug development professionals working in polymer data extraction.
Technical Background
The Dual Challenge of Polymer Data
Polymer data is characterized by its multi-scale nature and nomenclature inconsistency. The multi-scale structure means that a polymer's ultimate properties are determined by phenomena occurring at different scales: from the quantum mechanical (Ångstroms, femtoseconds) and atomistic (nanometers, nanoseconds) levels, through the mesoscopic (micrometers, microseconds), up to the macroscopic (millimeters and larger, seconds and longer) [39]. Simultaneously, the same polymer can be referred to by multiple names, such as its IUPAC name, common name, abbreviation, and trade name, creating significant challenges for data indexing and retrieval in automated systems [40]. For instance, a search for "polystyrene" might need to account for variations like "PS," "poly(1-phenylethene-1,2-diyl)," or trade names like "Styrofoam" to be comprehensive [40].
Impact on Materials Informatics
The inconsistency in polymer naming severely limits the broad application of materials informatics. As noted by Ramprasad et al., materials informatics requires data to be "reliable, uniform and stored in a controlled manner" [40]. The prevalent use of different naming conventions and abbreviations in publications confounds attempts to curate data robustly and consistently, which is a major impediment to the adoption of machine learning techniques [40]. This fragmentation stifles machine learning applications and delays the discovery of new materials, including those critical for next-generation energy technologies [14].
Quantitative Analysis of Polymer Data Complexity
Scale of the Data Extraction Challenge
Recent large-scale NLP efforts highlight the volume and complexity of polymer data embedded in scientific literature. The following table summarizes quantitative data from a recent study that processed millions of full-text articles.
Table 1: Scale of Polymer Data Extraction from Scientific Literature [1]
| Metric | Value | Description |
|---|---|---|
| Initial Corpus Size | ~2.4 million articles | Materials science journal articles from the last two decades |
| Polymer-Related Articles | ~681,000 documents | Identified by searching for 'poly' in titles and abstracts |
| Total Paragraphs Processed | 23.3 million paragraphs | Treated as individual text units for data extraction |
| Relevant Paragraphs | ~716,000 paragraphs (~3%) | Paragraphs containing complete, extractable property records after filtering |
| Extracted Property Records | >1 million records | Corresponding to 24 key properties of over 106,000 unique polymers |
Polymer Nomenclature Variations
The problem of nomenclature inconsistency is systematic. The following table classifies the primary types of polymer names and their characteristics, based on IUPAC standards and common usage.
Table 2: Classification of Polymer Nomenclature Systems [41] [42]
| Nomenclature Type | Basis | Examples | Key Characteristics |
|---|---|---|---|
| Source-Based | Monomer from which the polymer is derived | Polyethylene, Poly(methyl methacrylate) | Uses prefix "poly" followed by the monomer name; widely used in industry for simplicity. |
| Structure-Based | Constitutional Repeating Unit (CRU) | Poly(oxy(1-bromoethane-1,2-diyl)) | Provides detailed information about the polymer's molecular structure; follows IUPAC seniority rules for CRU selection. |
| Common Names/Abbreviations | Widespread usage and acceptance | PS (Polystyrene), PVC, PTFE (Teflon) | Simple and recognizable but often ambiguous without context; requires a lookup table for standardization. |
| Trade Names | Proprietary or branded products | Kevlar, Teflon, Styrofoam | Brand-specific; may not reveal chemical structure; intellectual property constraints. |
Experimental Protocols
Protocol 1: Standardized Polymer Name Normalization
Objective: To map diverse polymer name variations to a standardized, unique identifier, enabling accurate data aggregation and search.
Materials and Reagents:
- Input Data: Scientific text (e.g., journal article paragraphs, patents) containing polymer mentions.
- Reference Database: A curated polymer database (e.g., ChemProps, Polymer Genome) containing standard names, abbreviations, trade names, and their corresponding unique identifiers [40].
- NLP Tool: A large language model (LLM) or a dedicated algorithm (e.g., a multi-algorithm mapping methodology).
Methodology:
- Entity Recognition: Identify all strings within the text that refer to a polymer. This can be achieved using a Named Entity Recognition (NER) model trained on polymer science (e.g., MaterialsBERT) or via prompting an LLM with a relevant instruction [1].
- Candidate Generation: For each recognized polymer string, query the reference database to generate a list of candidate standard names and their associated unique identifiers (e.g., unique SMILES, uSMILES, or BigSMILES).
- Algorithmic Scoring: Employ a multi-algorithm mapping methodology. Assign a pre-optimized weight factor to each mapping algorithm (e.g., exact string match, synonym match, abbreviation expansion). Each algorithm "votes" for candidate polymers by adding its weight to their score [40].
- Selection and Validation: Select the candidate polymer with the highest aggregate score as the standardized mapping. Implement a confidence threshold; results below this threshold should be flagged for manual curation.
- Output: Return the standardized polymer name and its unique chemical identifier (e.g., uSMILES). This output can be delivered via a RESTful API for easy integration into other data systems [40].
Protocol 2: Multi-scale Data Extraction from Full-Text Articles
Objective: To automatically extract structured polymer-property data from the full text of scientific articles, accounting for information presented at different conceptual scales.
Materials and Reagents:
- Corpus: A collection of full-text journal articles (e.g., in PDF or XML format) [1].
- Computational Resources: Access to LLM APIs (e.g., GPT-3.5, LlaMa 2) and/or specialized NER models (e.g., MaterialsBERT) [1] [3].
- Property List: A predefined list of target polymer properties (e.g., glass transition temperature, tensile strength, bandgap).
Methodology:
- Text Pre-processing: Convert PDF articles to plain text and segment the text into manageable units, such as individual paragraphs [1] [3].
- Two-Stage Filtering: This critical step reduces computational cost by filtering out irrelevant text.
- Heuristic Filter: Pass each paragraph through property-specific heuristic filters (e.g., regular expressions) to detect the mention of a target polymer property or its co-referents [1].
- NER Filter: Apply an NER model to identify paragraphs containing a complete set of named entities:
material name,property name,numerical value, andunit. This confirms the existence of an extractable record [1].
- Information Extraction:
- LLM Approach: Feed the filtered paragraphs to an LLM using a carefully engineered prompt. The prompt should instruct the model to extract the polymer name, property, value, and unit, and output them in a structured format (e.g., JSON). Few-shot learning, providing a few annotated examples within the prompt, can significantly enhance performance [1].
- NER-Based Approach: Utilize a pipeline that first identifies all entities and then uses rule-based algorithms or dependency parsing to establish relationships between them [1].
- Data Structuring and Validation: Parse the LLM's structured output or the NER pipeline's results into a database. Implement validation checks, such as range checks for property values, and cross-verify a subset of extractions with manual annotations to assess accuracy [1] [3].
Visual Workflow for Polymer Data Extraction
The following diagram illustrates the end-to-end pipeline for extracting structured polymer data from unstructured text, integrating the protocols described above.
The Scientist's Toolkit: Research Reagent Solutions
This section details the key computational tools and resources essential for implementing the described polymer data extraction protocols.
Table 3: Essential Tools for Polymer NLP Research
| Tool/Resource | Type | Primary Function | Application Note |
|---|---|---|---|
| MaterialsBERT [1] | Named Entity Recognition (NER) Model | Identifies materials science-specific entities (e.g., polymer names, properties, values) in text. | A BERT model fine-tuned on materials science text; superior performance for polymer entity recognition compared to general-purpose models. |
| GPT-3.5 / LlaMa 2 [1] [3] | Large Language Model (LLM) | Performs end-to-end information extraction from paragraphs based on natural language prompts. | Effective in few-shot learning scenarios; cost-performance trade-offs must be evaluated for large-scale processing. |
| ChemProps API [40] | Standardization API | Maps common polymer names, abbreviations, and trade names to a standard name and unique SMILES. | A RESTful API that solves the polymer indexing issue; enables accurate "search by SMILES" across different databases. |
| Polymer Scholar [1] | Public Database | A repository of extracted polymer-property data for exploration and analysis. | Contains over one million property records for >106,000 unique polymers; a valuable resource for data mining and validation. |
| BigSMILES [40] | Chemical Identifier | An extension of SMILES notation for representing the stochastic nature of polymers. | A promising solution for consistent polymer representation once canonicalized; not yet universally adopted. |
Improving Model Interpretability and Explainability in Deep Learning Approaches
The adoption of deep learning in high-stakes scientific domains, such as natural language processing (NLP) for polymer data extraction, necessitates models whose predictions are not only accurate but also interpretable and explainable. In polymer informatics and drug development, researchers need to extract precise information about polymer properties, synthesis conditions, and performance characteristics from vast scientific literature. Model interpretability—the ability to understand a model's internal mechanisms—and explainability—the ability to explain specific predictions—become crucial for validating extracted data, building scientific trust, and guiding experimental design [43]. This document presents application notes and experimental protocols for implementing interpretable deep learning approaches within polymer NLP research contexts.
Quantitative Performance of Interpretable Methods
The field has seen explosive growth, with annual publications on deep learning interpretability increasing from just 4 in 2014 to 1,894 in 2023 [43]. Different interpretability approaches offer distinct performance characteristics, which researchers must consider when selecting methods for polymer data extraction tasks.
Table 1: Performance Comparison of Interpretable Deep Learning Methods in NLP
| Method Category | Representative Models | Key Performance Metrics | Polymer NLP Applicability |
|---|---|---|---|
| Post-hoc Explanation | Layer-wise Integrated Gradients (LIG) | N/A (Provides explanation faithfulness) | Explaining entity extraction from polymer literature; identifying key words for property prediction [44]. |
| Inherently Interpretable | Prototype-based Networks (e.g., This Reads Like That) | Improved predictive performance & explanation faithfulness on AG News, RT Polarity [45]. | Classifying polymer types; extracting synthesis method entities with self-explanatory similarity comparisons. |
| Model-Specific | Fine-tuned Transformer (BERT) | F-Measure: 0.89 (3-entity extraction) [44]. | Extracting polymer-property triplets (subject, action, resource) from scientific text. |
| Model-Specific | Fine-tuned Transformer (ModernBERT) | F-Measure: 0.84 (5-entity extraction) [44]. | Extracting complex relationships (subject, action, resource, condition, purpose) from polymer data. |
Experimental Protocols for Interpretable Polymer NLP
Protocol: Explainable Entity Extraction for Polymer Data
This protocol details the use of transformer models with explainability components for extracting key entities (e.g., polymer names, properties, values) from scientific literature.
Research Reagents & Materials: Table 2: Essential Research Reagents for Interpretable Polymer NLP
| Reagent / Tool | Specification / Version | Function in Protocol |
|---|---|---|
| BERT Model | bert-base-uncased or domain-specific variant |
Base pre-trained model for fine-tuning on polymer corpus; provides foundational language understanding. |
| ModernBERT Model | modernbert-base |
Advanced transformer architecture for more complex entity extraction tasks with five or more entity types. |
| Polymer NER Dataset | Annotated polymer scientific abstracts (IOB format) | Gold-standard data for training and evaluating named entity recognition models; should include entities relevant to polymer science. |
| Layer Integrated Gradients (LIG) | Custom implementation or library (e.g., Captum) | Explainability technique to determine input token contribution to model predictions; validates extraction logic. |
| Optuna Framework | v3.3+ | Hyperparameter optimization library for systematically tuning model parameters to maximize extraction performance. |
Procedure:
- Data Preparation and Preprocessing:
- Corpus Collection: Assemble a corpus of polymer-related scientific literature from sources like PubMed, Springer, and ACS Publications.
- Annotation: Manually annotate sentences using the IOB (Inside, Outside, Beginning) tagging schema. For initial tasks, use a 3-entity paradigm:
B-POLYMER,I-PROPERTY,I-VALUE. For complex extractions, use a 5-entity paradigm:B-POLYMER,I-PROPERTY,I-VALUE,I-CONDITION,I-PURPOSE[44]. - Text Cleaning: Convert text to lowercase, remove special characters, replace tabs with spaces, and collapse multiple spaces. Split the dataset into training (80%), validation (10%), and test (10%) sets.
Hyperparameter Tuning:
- Utilize the Optuna framework for Bayesian optimization [44].
- Define the search space to include learning rate (
1e-5to1e-3), batch size (16,32), optimizer (AdamW,Adam), dropout rate (0.1to0.4), and label smoothing. - Run a minimum of 20 trials to identify the optimal configuration for your specific polymer dataset.
Model Fine-tuning:
- Initialize a pre-trained BERT or ModernBERT model for a token classification task.
- Fine-tune the model using the training set and optimal hyperparameters. Use the validation set for early stopping to prevent overfitting.
Model Evaluation:
- Evaluate the fine-tuned model on the held-out test set.
- Report standard performance metrics: Precision, Recall, and F-Measure for each entity type and overall.
Explainability Analysis:
- Apply the Layer Integrated Gradients (LIG) method to the fine-tuned model's predictions on the test set [44].
- This analysis produces attribution scores for each input token, indicating its importance in the model's decision to assign a specific entity label. This is crucial for verifying that the model is relying on scientifically relevant terms (e.g., "Young's modulus," "PMMA") rather than spurious correlations.
Diagram 1: Explainable Polymer NER Workflow
Protocol: Interpretable Prototype-based Classification
This protocol employs prototype-based deep learning models for tasks like polymer family classification, where the prediction is inherently interpretable by design.
Procedure:
- Data and Embedding:
- Prepare a dataset of polymer-related text snippets (e.g., abstract sentences) labeled with categories (e.g., "thermoplastic," "elastomer," "composite").
- Generate pre-trained sentence embeddings (e.g., using Sentence-BERT) for all data points.
Model Training:
- Implement a prototypical network that learns a set of prototype vectors in the embedding space, each representative of a polymer class.
- Incorporate a learned weighted similarity measure that enhances similarity computation by focusing on informative dimensions of the sentence embeddings [45]. This allows the model to prioritize specific polymer-related features.
Prediction and Explanation:
- Classify a new sentence by finding the closest prototype(s) in the learned, weighted similarity space.
- The explanation for a prediction is naturally provided by the most similar prototypes. The model's decision can be understood as: "This polymer description reads like that known prototype of polyurethanes."
Explanation Enhancement:
- Apply a post-hoc explainability mechanism that extracts prediction-relevant words from both the input sentence and the most influential prototype sentences [45]. This provides a granular, token-level rationale for the classification.
Diagram 2: Prototype-Based Classification
Visualization and Color Contrast Guidelines
All diagrams and visual explanations generated must adhere to accessibility standards to ensure clarity for all researchers, including those with visual impairments. The following guidelines and color palette are mandatory.
Color Palette: #4285F4 (Blue), #EA4335 (Red), #FBBC05 (Yellow), #34A853 (Green), #FFFFFF (White), #F1F3F4 (Light Gray), #202124 (Dark Gray), #5F6368 (Medium Gray).
Contrast Rules:
- Text Contrast: Normal text must have a contrast ratio of at least 4.5:1 against its background. Large text (approx. 18pt or 14pt bold) must have a ratio of at least 3:1 [46] [47]. For example,
#202124(text) on#FFFFFF(background) provides a ratio of >16:1. - UI/Graphical Elements: Icons, chart lines, and diagram nodes must have a contrast ratio of at least 3:1 against adjacent colors [47].
- Diagram Implementation: In DOT scripts, explicitly set
fontcolorandfillcolorfor all nodes containing text to ensure high contrast. Avoid combinations like#FBBC05(yellow) on#FFFFFF(white), which has a low ratio.
Integrating interpretability and explainability into deep learning models for polymer NLP is not merely a technical enhancement but a scientific necessity. The protocols outlined—for explainable entity extraction and interpretable prototype-based classification—provide a concrete pathway for researchers to develop models that are both powerful and transparent. By employing these methods and adhering to robust visualization standards, scientists can build trustworthy systems that not only extract critical polymer data but also provide the explanations and rationale needed to accelerate materials discovery and drug development.
Computational Resource Management and Pipeline Efficiency Optimization
The application of Natural Language Processing (NLP) and Large Language Models (LLMs) to polymer data extraction represents a paradigm shift in materials informatics, enabling the mining of vast scientific literature corpora at unprecedented scale [8]. However, this approach demands sophisticated computational resource management and pipeline optimization strategies to balance extraction quality with practical constraints. As polymer datasets grow exponentially, efficient resource allocation becomes critical for sustainable research. This document provides detailed application notes and protocols for optimizing computational resources in NLP-driven polymer data extraction pipelines, addressing the specific challenges of processing heterogeneous polymer literature while maintaining cost-effectiveness and performance efficiency.
Performance Benchmarking and Model Selection
Quantitative Comparison of Extraction Approaches
Selecting appropriate models requires careful benchmarking across multiple performance dimensions. The following table summarizes key performance metrics for three model types applied to polymer data extraction:
Table 1: Performance comparison of data extraction models for polymer science applications
| Performance Metric | MaterialsBERT (NER) | GPT-3.5 | LlaMa 2 |
|---|---|---|---|
| Extraction Quantity | ~300,000 records from 130,000 abstracts [1] | Over 1 million records from 681,000 articles [1] | Comparable to GPT-3.5 [1] |
| Extraction Quality | High precision on entity recognition [1] | Contextual understanding, potential hallucinations [1] | Contextual understanding, potential hallucinations [1] |
| Computational Time | Optimized for specific NER tasks [1] | Significant for large corpora [1] | Significant for large corpora [1] |
| Monetary Cost | Lower after initial setup [1] | Significant API costs [1] | Significant computational resources [1] |
| Entity Relationship Handling | Limited across extended passages [1] | Excellent contextual relationship mapping [1] | Excellent contextual relationship mapping [1] |
| Polymer Nomenclature Flexibility | Challenged by synonyms and acronyms [1] | Adaptable to non-standard polymer terminology [1] | Adaptable to non-standard polymer terminology [1] |
Model Selection Protocol
Protocol 1: Strategic Model Selection for Polymer Data Extraction
Objective: Systematically select optimal extraction models based on project constraints and data characteristics.
Materials:
- Corpus of polymer literature (e.g., 2.4 million articles) [1]
- Computational budget allocation
- Required performance thresholds
- Target polymer properties (e.g., 24 key properties) [1]
Procedure:
- Define Extraction Scope: Identify target polymer properties and required data structure
- Assess Corpus Characteristics: Evaluate polymer nomenclature complexity and data distribution
- Prioritize Performance Dimensions: Rank quantity, quality, time, and cost based on project goals
- Hybrid Approach Design: Combine NER and LLM strengths for specific pipeline stages
- Validation Framework: Establish quality metrics for each extraction approach
Applications:
- Use MaterialsBERT for high-volume, well-structured polymer property extraction [1]
- Deploy GPT-3.5 for complex relationship extraction and non-standard nomenclature [1]
- Implement LlaMa 2 for open-source solutions with sufficient computational resources [1]
Pipeline Architecture and Optimization Strategies
Hierarchical Filtering Workflow
Efficient polymer data extraction requires a multi-stage filtering approach to minimize computational load while maximizing relevant data capture. The following diagram illustrates the optimized extraction workflow:
Diagram 1: Polymer data extraction pipeline with hierarchical filtering
Cost Optimization Protocol
Protocol 2: Computational Cost Optimization for LLM-Based Extraction
Objective: Implement strategies to reduce computational expenses while maintaining extraction quality.
Materials:
- Pre-processed text paragraphs
- Property-specific heuristic filters
- Named Entity Recognition model (e.g., MaterialsBERT) [1]
- LLM API access (e.g., GPT-3.5, LlaMa 2) [1]
Procedure:
- Heuristic Filter Implementation:
- Develop property-specific keyword lists for initial filtering
- Process 23.3 million paragraphs to identify ~2.6 million relevant paragraphs (11% initial filter) [1]
- Apply lightweight pattern matching to exclude clearly irrelevant content
NER Filter Application:
Selective LLM Deployment:
- Apply LLMs only to NER-filtered paragraphs
- Implement few-shot learning with optimized examples [1]
- Batch process paragraphs to reduce API overhead
Validation:
- Compare extraction results between NER-only and LLM-enhanced approaches
- Measure precision/recall for target polymer properties
- Calculate cost per extracted record for optimization assessment
Resource Allocation and Technical Specifications
Computational Resource Requirements
Table 2: Computational resource specifications for polymer data extraction
| Resource Component | Specifications | Optimization Strategies |
|---|---|---|
| Processing Corpus | 2.4 million materials science articles [1] | Focus on polymer-related subset (681,000 articles) |
| Text Units | 23.3 million paragraphs [1] | Two-stage filtering reduces to 3% for LLM processing [1] |
| LLM API Costs | Significant monetary expenditure [1] | Selective prompting, few-shot learning, batching [1] |
| Energy Consumption | High carbon footprint [1] | Local models for initial processing, cloud for specific tasks |
| Storage Requirements | Structured database for >1 million polymer records [1] | Efficient indexing for polymer properties and structures |
Research Reagent Solutions
Table 3: Essential computational reagents for polymer data extraction
| Reagent | Function | Implementation Example |
|---|---|---|
| MaterialsBERT | Named Entity Recognition for materials science [1] | Identify polymer names, properties, values in text [1] |
| GPT-3.5/LlaMa 2 | Relationship extraction and contextual understanding [1] | Process complex polymer descriptions and non-standard nomenclature [1] |
| Heuristic Filters | Initial relevance screening [1] | Property-specific keyword matching to reduce processing load [1] |
| UMAP Dimensionality Reduction | Visualization of high-dimensional polymer data [48] | Analyze relationships between polymer properties and structure [48] |
| Particle Swarm Optimization | Parameter optimization for analysis pipelines [48] | Adaptive weighting of quality characteristics in multivariate data [48] |
Advanced Optimization Techniques
In-Context Learning Optimization
Protocol 3: Few-Shot Learning Implementation for Polymer Extraction
Objective: Maximize LLM performance with minimal examples through optimized prompt engineering.
Materials:
- Curated set of polymer-property examples
- LLM with instruction-following capability
- Template-based prompt structure
Procedure:
- Example Selection:
- Choose diverse polymer classes (polyolefins, polyesters, etc.)
- Include varied property types (mechanical, thermal, optical)
- Incorporate non-standard nomenclature examples
Prompt Structure Design:
- Establish clear input-output format
- Include explicit instructions for unit handling
- Define material-property-value relationships
Iterative Refinement:
- Test with validation set of known extractions
- Modify examples based on failure patterns
- Optimize for ambiguous cases and boundary conditions
Multivariate Analysis Integration
The Variable-Weight Uniform Manifold Approximation and Projection (VUMAP) algorithm provides advanced capability for analyzing complex polymer property relationships while optimizing computational efficiency [48]. The following diagram illustrates the VUMAP integration for polymer data analysis:
Diagram 2: VUMAP workflow for polymer data analysis
Protocol 4: VUMAP Implementation for Polymer Data Visualization
Objective: Apply variable-weight dimensionality reduction to identify complex polymer property relationships.
Materials:
- Extracted polymer property dataset
- K-Means++ clustering implementation [48]
- Particle Swarm Optimization algorithm [48]
- UMAP dimensionality reduction package
Procedure:
- Data Preprocessing:
- Normalize polymer property values
- Handle missing data through imputation
- Encode categorical polymer characteristics
Dynamic Weight Assignment:
VUMAP Dimensionality Reduction:
Applications:
- Identification of polymer families with similar property profiles
- Visualization of structure-property relationships
- Quality control assessment for polymer manufacturing [48]
Effective computational resource management in polymer data extraction pipelines requires strategic model selection, hierarchical filtering, and optimized processing protocols. The integration of traditional NER approaches with modern LLMs, coupled with advanced dimensionality reduction techniques, enables comprehensive polymer data extraction while managing computational costs. These protocols provide researchers with structured methodologies for implementing efficient NLP-driven polymer informatics pipelines, accelerating materials discovery through systematic literature mining.
The application of Natural Language Processing (NLP) and Large Language Models (LLMs) is revolutionizing materials science research by enabling the automated extraction of structured data from vast scientific literature repositories. For polymer science specifically, where historical data remains trapped in unstructured text formats within millions of journal articles, integrating these technologies with existing laboratory workflows presents both tremendous opportunities and significant implementation challenges. This paradigm shift from traditional experience-driven methods to data-driven approaches is critical for accelerating polymer discovery and development cycles [49]. The integration of automated information extraction pipelines allows researchers to systematically compile processing parameters, property data, and synthesis conditions into queryable databases, thereby reducing reliance on trial-and-error methodologies and bridging correlations between material formulation and application performance [3]. This document provides detailed application notes and protocols for effectively combining NLP technologies with established laboratory workflows in polymer research, focusing on practical implementation strategies, performance optimization, and seamless integration with existing research infrastructures.
Current State of NLP in Materials Science
The field of materials informatics has historically suffered from lack of data readiness and accessibility, with substantial amounts of historical data trapped in published literature [1]. Natural Language Processing techniques implemented in materials science seek to automatically extract materials insights, properties, and synthesis data from text documents to advance materials discovery [1]. With the advent of modern machine learning and artificial intelligence techniques, transformer-based architectures like BERT have demonstrated superior performance in capturing contextual and semantic relationships within scientific texts [1]. More recently, Large Language Models such as GPT, LlaMa, and Falcon have gained significant attention for their remarkable performance in handling various NLP tasks, showcasing particular robustness in high-performance text classification, named entity recognition (NER), and extractive question answering with limited datasets [1] [8].
The development of materials-specific language models like MaterialsBERT has demonstrated significant advantages for domain-specific extraction tasks, outperforming general-purpose models on materials science-specific data extraction [1]. These models have successfully processed hundreds of thousands of polymer-related articles, extracting over one million records corresponding to numerous properties of unique polymers [1]. The continuous evolution of pre-trained LLMs has further expanded capabilities through massive parameter scaling, enabling sophisticated internal representations that spring up capabilities unattainable in smaller architectures, particularly in classification of entities in longer contexts and extraction of more complex semantic relations [3].
Table 1: Evolution of NLP Approaches in Materials Science
| Approach | Key Characteristics | Performance Advantages | Implementation Complexity |
|---|---|---|---|
| Rule-Based Systems | Handcrafted rules based on expert knowledge | Effective for narrowly defined problems | High initial development effort |
| Traditional Machine Learning | Requires feature engineering and annotated corpora | Improved over rule-based systems | Moderate to high annotation burden |
| BERT-based Models (e.g., MaterialsBERT) | Transformer architecture, domain-specific pre-training | Superior contextual understanding | Moderate fine-tuning requirements |
| Large Language Models (LLMs) | Massive parameter scaling, instruction following | Excellent few-shot/zero-shot performance | High computational requirements |
NLP Integration Framework for Polymer Research
Pipeline Architecture and Components
The successful integration of NLP technologies into polymer research laboratories requires a structured framework that encompasses both technical implementation and workflow adaptation. A robust NLP extraction pipeline for polymer science typically employs a dual-stage approach consisting of heuristic filtering and named entity recognition (NER) filtering to identify relevant text segments containing extractable data [1]. This framework processes individual paragraphs as text units, applying property-specific heuristic filters to detect mentions of target polymer properties or co-referents, followed by NER filters to confirm the existence of complete extractable records containing material names, property names, values, and units [1].
The pipeline begins with corpus assembly and pre-processing, where journal articles are indexed and downloaded from authorized publishers, with polymer-related documents identified through targeted keyword searches [1]. The text is then segmented into manageable units (typically paragraphs), which undergo the dual-stage filtering process to identify texts with high potential for containing extractable polymer-property data. The core extraction phase utilizes either specialized NER models or LLMs to identify materials, properties, values, and units, establishing relationships between these entities and outputting structured data compatible with laboratory information management systems [1] [3].
Laboratory Workflow Integration Points
Effective integration of NLP technologies requires identifying key touchpoints with existing laboratory workflows. Primary integration points include literature-based research planning, where extracted data informs experimental design; results comparison and analysis, where newly generated laboratory data is contextualized against historical literature; and knowledge gap identification, where comprehensive literature analysis reveals underexplored research areas [1] [49]. The NLP pipeline serves as a force multiplier that enhances researcher efficiency rather than replacing domain expertise, enabling scientists to focus on high-value experimental design and interpretation tasks while automated systems handle large-scale data aggregation and preliminary analysis.
Laboratory information management systems (LIMS) represent the most critical integration point, where extracted structured data must be formatted for seamless incorporation. Implementing standardized data schemas that accommodate both experimentally generated and literature-derived data ensures consistent representation and querying capabilities [3]. Additionally, establishing bidirectional data flow allows laboratory-generated results to refine and validate the NLP extraction process, creating a virtuous cycle of improvement where domain expertise enhances algorithmic performance and comprehensive data access informs experimental design.
Experimental Protocols and Methodologies
Protocol 1: Polymer Property Data Extraction from Literature
Objective: Automate extraction of polymer property data from scientific literature to build comprehensive polymer databases.
Materials and Reagents:
- Corpus of polymer-related scientific articles (PDF format)
- Computational resources (CPU/GPU infrastructure)
- NLP models (MaterialsBERT, GPT variants, or LlaMa)
- Data storage and management system
Methodology:
- Corpus Assembly: Collect full-text journal articles from authorized publishers including Elsevier, Wiley, Springer Nature, American Chemical Society, and Royal Society of Chemistry. Index articles through Crossref database or similar services [1].
- Document Identification: Identify polymer-related documents by searching for key terms (e.g., "poly") in titles and abstracts. This typically identifies approximately 28% of materials science articles as polymer-related [1].
- Text Segmentation: Process identified documents into individual paragraphs as text units. A corpus of 681,000 polymer-related documents typically yields approximately 23.3 million paragraphs [1].
- Heuristic Filtering: Apply property-specific heuristic filters to detect paragraphs mentioning target polymer properties or co-referents manually curated via literature review. This stage typically filters ~11% of paragraphs for further processing [1].
- NER Filtering: Apply named entity recognition filter to identify paragraphs containing all necessary named entities (material name, property name, property value, unit) to confirm existence of complete extractable records. This refined filtering yields approximately 3% of original paragraphs [1].
- Data Extraction: Process filtered paragraphs through LLM or NER-based extraction models to identify materials, properties, values, and units, establishing relationships between these entities.
- Structured Output Generation: Convert extracted information into structured format compatible with laboratory databases and analysis tools.
- Quality Validation: Implement manual sampling and validation procedures to assess extraction accuracy and identify error patterns.
Expected Outcomes: Successful implementation typically extracts over one million property records from approximately 681,000 polymer-related articles, covering multiple properties of over 106,000 unique polymers [1].
Protocol 2: Processing Parameter Extraction for Polymer Processing Database
Objective: Extract polymer processing parameters and conditions from literature to build processing-property relationship databases.
Materials and Reagents:
- Scientific literature focusing on polymer processing techniques
- Fine-tuned LLM (e.g., LlaMa-2-7B-Chat)
- Prompt engineering framework
- Structured output parsing system
Methodology:
- Text Preprocessing: Compress context length to include only specific paragraphs related to processing parameters before extraction to meet model input length requirements [3].
- Relevant Paragraph Identification: Use similarity search based on regular expressions to identify sections containing processing information, focusing on methodology and results sections [3].
- Prompt Engineering: Develop structured prompts that define entity types (processing method, parameters, values, units) and require JSON format output. Include domain-specific examples for few-shot learning [3].
- Model Inference: Process relevant paragraphs through fine-tuned LLM using appropriate computational resources.
- Output Parsing: Extract and validate JSON outputs, handling formatting errors and inconsistencies.
- Error Analysis and Refinement: Categorize error types (factual hallucinations, negation ignorance, numeric errors, entity confusion) and implement iterative refinement cycles [3].
- Database Integration: Structure extracted processing parameters into searchable database format with links to resulting properties.
Expected Outcomes: Implementation using QLoRA framework enables highly accurate extraction (91.1% accuracy, 98.7% F1-score) with minimal data (224 samples) and computational overhead [3].
Table 2: Performance Comparison of NLP Approaches for Polymer Data Extraction
| Extraction Model | Data Quantity | Quality Metrics | Computational Requirements | Implementation Considerations |
|---|---|---|---|---|
| MaterialsBERT | 300,000+ polymer-property records from ~130,000 abstracts | Superior performance on materials-specific datasets | Moderate computational requirements | Requires domain-specific pre-training |
| GPT-3.5 | Over one million records from ~681,000 full-text articles | High performance in few-shot/zero-shot learning | Significant API costs | Optimize through careful prompt engineering |
| LlaMa 2 | Comparable extraction scale to GPT-3.5 | Competitive with commercial models | Open-source, reduced operational costs | Requires technical expertise for optimization |
| Fine-tuned LlaMa-2-7B | Specialized processing parameter extraction | 91.1% accuracy, 98.7% F1-score | Efficient fine-tuning with QLoRA | Minimal data requirements (224 samples) |
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Research Reagents for NLP-Polymer Research Integration
| Reagent Solution | Function | Implementation Notes |
|---|---|---|
| Polymer Literature Corpus | Foundation for data extraction and model training | ~2.4 million materials science articles from last two decades; 681,000 polymer-specific documents [1] |
| Named Entity Recognition Models | Identify key entities in scientific text | MaterialsBERT demonstrates superior performance for materials science tasks [1] |
| Large Language Models | Flexible extraction through prompt engineering | GPT-3.5, LlaMa 2, or fine-tuned variants balance performance and cost [1] [3] |
| Computational Infrastructure | Enable model training and inference | CPU/GPU resources commensurate with model size and processing volume |
| Structured Database Schema | Organize extracted information for utilization | Compatible with laboratory information management systems [3] |
| Quality Validation Framework | Assess extraction accuracy and reliability | Manual sampling, error categorization, and iterative improvement cycles [3] |
Integration Workflow and Data Flow
The complete integration of NLP technologies with laboratory workflows follows a systematic process that transforms unstructured literature into actionable insights for experimental planning and analysis. The workflow encompasses both the technical extraction pipeline and the research feedback loop, creating a synergistic relationship between computational extraction and laboratory experimentation.
Performance Optimization and Cost Management
Implementing NLP technologies within research laboratories requires careful consideration of performance optimization and cost management strategies. Different model architectures present distinct trade-offs between extraction quality, computational requirements, and operational costs. Commercial LLMs like GPT-3.5 demonstrate excellent performance in few-shot and zero-shot learning scenarios but incur significant monetary costs due to API usage, particularly when processing millions of scientific paragraphs [1]. In contrast, open-source models like LlaMa 2 offer reduced operational costs but require greater technical expertise for optimization and deployment.
Effective cost optimization strategies include implementing efficient filtering mechanisms to reduce unnecessary LLM prompts, with dual-stage heuristic and NER filtering typically reducing processing volume to approximately 3% of original paragraphs [1]. Fine-tuning approaches like QLoRA enable high-accuracy extraction with minimal data samples (as few as 224 samples) and computational overhead [3]. Additionally, targeted model selection based on specific extraction tasks—using specialized NER models for straightforward entity recognition and reserving LLMs for complex relationship extraction—optimizes both performance and resource utilization. Continuous performance monitoring and error analysis, particularly addressing common issues like factual hallucinations, negation ignorance, and numeric errors, further enhances extraction efficiency and reduces costly reprocessing requirements [3].
Benchmarking NLP Performance: Accuracy, Reliability, and Comparative Analysis
Validation Frameworks for Extracted Polymer Data
The exponential growth of polymer science literature presents a significant challenge for researchers attempting to manually extract and validate material property data [9] [50]. Natural language processing (NLP) offers powerful solutions for automated data extraction, but ensuring the accuracy and reliability of this extracted information requires robust validation frameworks [51]. This application note details protocols and methodologies for validating polymer data extracted from scientific literature using NLP techniques, framed within the broader context of polymer informatics research. We present a structured approach combining quantitative metrics, experimental validation, and practical tools to assist researchers in establishing trustworthy data pipelines for materials discovery and development.
Data Extraction and Validation Workflow
Automated data extraction from polymer literature involves multiple NLP components, including named entity recognition (NER) and relationship extraction, typically powered by specialized language models like MaterialsBERT or large language models (LLMs) such as GPT-3.5 and LlaMa 2 [9] [51]. The validation of extracted data occurs at multiple stages to ensure data quality and reliability before integration into knowledge bases.
Workflow Visualization
The following diagram illustrates the comprehensive pipeline for extracting and validating polymer data from scientific literature:
Performance Comparison of Extraction Methods
Different NLP approaches offer varying advantages for polymer data extraction. The table below summarizes the performance characteristics of three primary methods based on large-scale implementation studies:
Table 1: Performance Comparison of Polymer Data Extraction Methods
| Extraction Method | Data Quantity | Quality (Precision) | Processing Time | Computational Cost | Best Use Cases |
|---|---|---|---|---|---|
| MaterialsBERT NER [9] | ~300,000 records from 130,000 abstracts | High (domain-specific training) | 60 hours for 130,000 abstracts | Moderate | High-volume extraction of specific property types |
| GPT-3.5 LLM [51] | Over 1 million records from 681,000 articles | High with proper prompting | Variable (API-dependent) | High (monetary cost) | Complex relationship extraction from full texts |
| LlaMa 2 LLM [51] | Comparable to GPT-3.5 | Slightly lower than GPT-3.5 | Slower than GPT-3.5 | High (computational resources) | Open-source alternative for sensitive data |
Experimental Protocols
Protocol 1: Annotation and Training Set Creation
This protocol details the creation of labeled datasets for training and validating NER models for polymer data extraction.
Materials and Equipment
- Text Corpus: Collection of polymer science abstracts or full-text articles (e.g., 2.4 million materials science papers) [9]
- Annotation Software: Tools such as Prodigy (https://prodi.gy) or similar annotation platforms [9]
- Domain Experts: Minimum of three annotators with expertise in polymer science
- Annotation Guidelines: Comprehensive documentation defining entity types and labeling rules
Procedure
- Corpus Filtering: Filter the initial corpus to polymer-relevant documents using keyword searches (e.g., "poly") and regular expressions to identify abstracts containing numeric information [9].
- Ontology Definition: Establish a clear ontology of entity types relevant to polymer property extraction. Core entities should include:
- POLYMER: Specific polymer names and compounds
- POLYMERCLASS: Categories or classes of polymers
- PROPERTYNAME: Names of material properties
- PROPERTYVALUE: Numerical values and their units
- MONOMER: Monomer constituents
- ORGANICMATERIAL: Other organic materials mentioned
- INORGANICMATERIAL: Other inorganic materials mentioned
- MATERIALAMOUNT: Quantities of materials [9]
- Pre-annotation: Use dictionary-based approaches to automatically pre-annotate entities where possible to accelerate the annotation process [9].
- Multi-round Annotation: Conduct annotation over multiple rounds with a small sample of abstracts in each round. Refine annotation guidelines between rounds and re-annotate previous abstracts using refined guidelines [9].
- Inter-annotator Agreement Assessment: Select a subset of abstracts (e.g., 10) to be annotated by all annotators. Calculate Cohen's Kappa and Fleiss Kappa metrics to ensure annotation consistency. Target values should exceed 0.85 for reliable annotations [9].
- Dataset Splitting: Divide the annotated dataset into training (85%), validation (5%), and test (10%) sets [9].
Protocol 2: Model Training and Evaluation
This protocol outlines the process for training and evaluating NER models for polymer data extraction.
Materials and Equipment
- Computing Resources: GPU-enabled workstations or servers
- Deep Learning Framework: PyTorch or TensorFlow
- Pre-trained Language Models: MaterialsBERT, PubMedBERT, or domain-specific variants
- Annotation Datasets: Labeled data from Protocol 1
Procedure
- Model Architecture Selection: Implement a BERT-based encoder to generate contextual token representations, followed by a linear layer with softmax non-linearity for entity type prediction [9].
- Input Processing: Tokenize input texts and truncate sequences longer than 512 tokens, as this represents the standard input limit for BERT models [9].
- Model Training:
- Initialize with a pre-trained BERT model (e.g., MaterialsBERT trained on 2.4 million materials science abstracts) [9]
- Use cross-entropy loss for training
- Apply dropout in the linear layer (probability = 0.2)
- Train on the training set while monitoring performance on the validation set
- Model Evaluation:
- Evaluate the trained model on the held-out test set
- Calculate precision, recall, and F1-score for each entity type
- Compare performance against baseline models (e.g., BioBERT, ChemBERT) [9]
- Error Analysis: Examine cases where the model fails to correctly identify entities and refine the training data or model architecture accordingly.
Protocol 3: LLM-Based Extraction with Validation
This protocol describes the use of large language models for data extraction with integrated validation steps.
Materials and Equipment
- LLM Access: API access to commercial LLMs (e.g., GPT-3.5) or local deployment of open-source models (e.g., LlaMa 2) [51]
- Computing Resources: Sufficient computational capacity for processing large text corpora
- Prompt Engineering Templates: Pre-designed prompts for property extraction
Procedure
- Two-Stage Filtering:
- Apply property-specific heuristic filters to identify paragraphs mentioning target polymer properties (~11% of paragraphs typically pass this stage) [51]
- Implement NER filtering to identify paragraphs containing all necessary named entities (material name, property name, value, unit), further reducing the dataset to ~3% of original paragraphs [51]
- Few-Shot Prompt Design: Develop prompts with 3-5 examples of correct extraction patterns to guide the LLM's output format and improve accuracy [51].
- Dual-Model Extraction: Process filtered paragraphs through both MaterialsBERT and LLM pipelines independently to enable cross-validation [51].
- Record Reconciliation: Compare extractions from both methods and flag discrepancies for manual review.
- Cost Optimization: For LLM-based extraction, implement careful filtering to reduce the number of API calls, as this represents the primary cost factor [51].
The Scientist's Toolkit
Table 2: Essential Research Reagents and Computational Tools for Polymer Data Extraction
| Tool/Resource | Type | Function | Application Context |
|---|---|---|---|
| MaterialsBERT [9] | Language Model | Domain-specific NER for materials science | Pre-trained on 2.4 million materials science abstracts; optimal for polymer entity recognition |
| Polymer Scholar [51] | Database Platform | Public repository for extracted polymer data | Hosts >1 million property records; enables data exploration and validation |
| Prodigy [9] | Annotation Tool | Manual annotation of training datasets | Used for creating labeled datasets with high inter-annotator agreement (Fleiss Kappa >0.88) |
| GPT-3.5/Turbo [51] | Large Language Model | Relationship extraction from complex text | Effective for full-text processing with appropriate few-shot prompting |
| LlaMa 2 [51] | Large Language Model | Open-source alternative for data extraction | Suitable for environments with data privacy concerns or limited API access |
| ColorBrewer [52] | Visualization Tool | Accessible color palette generation | Ensures data visualizations are colorblind-safe and effectively communicate patterns |
| Design of Experiments [53] | Statistical Framework | Systematic optimization of extraction parameters | Useful for balancing precision, recall, and computational costs in pipeline design |
Validation Metrics and Framework
Establishing comprehensive validation metrics is crucial for assessing the quality of extracted polymer data. The following diagram illustrates the multi-faceted validation approach:
Quantitative Validation Metrics
The following metrics should be calculated to assess extraction quality:
Table 3: Key Validation Metrics for Extracted Polymer Data
| Metric Category | Specific Metrics | Target Values | Calculation Method |
|---|---|---|---|
| Entity Recognition | Precision, Recall, F1-score (per entity type) | >0.85 F1 for critical entities | True Positives / (True Positives + False Positives) etc. |
| Annotation Quality | Cohen's Kappa, Fleiss Kappa | >0.85 | Inter-annotator agreement measures [9] |
| Record Completeness | Percentage of records with all required entities | >90% | (Complete records / Total records) × 100 |
| Cross-Model Agreement | Percentage agreement between different extraction methods | >80% | (Agreeing records / Total records) × 100 [51] |
Implementing robust validation frameworks is essential for ensuring the reliability of polymer data extracted from scientific literature using NLP methods. The protocols and metrics outlined in this application note provide researchers with practical tools for establishing trustworthy data pipelines. By combining automated metrics with manual verification and cross-model validation, researchers can build high-quality datasets that support advanced materials informatics applications, including property prediction models and materials discovery platforms. The continued development of domain-specific language models and validation methodologies will further enhance our ability to leverage the vast knowledge embedded in the polymer science literature.
The exponential growth of materials science literature presents a significant bottleneck in connecting new discoveries with established knowledge [54] [55]. Natural Language Processing (NLP), particularly Named Entity Recognition (NER), has emerged as a critical technology for automating the extraction of structured information from scientific texts, thereby accelerating materials discovery [9] [18]. Within this domain, specialized language models pre-trained on scientific corpora have demonstrated superior performance compared to general-purpose models [54] [18]. This Application Note provides a detailed comparative analysis of MaterialsBERT against other prominent models, including MatBERT, SciBERT, and domain-specific adaptations, focusing on their performance in materials science NER tasks. The content is framed within a broader research initiative on NLP for polymer data extraction, providing valuable insights for researchers, scientists, and professionals engaged in data-driven materials development.
MaterialsBERT is a transformer-based language model specifically pre-trained on a large corpus of materials science literature. It builds upon the BERT architecture and is adapted to the materials domain through continued pre-training on a carefully curated corpus comprising approximately 2.4 million materials science abstracts [9] or 150,000 full-text papers focusing on key subfields like inorganic glasses, metallic glasses, alloys, and cement [18]. This extensive domain-specific pre-training enables MaterialsBERT to develop a nuanced understanding of materials science terminology, notations, and context, which is crucial for accurate information extraction.
Comparative Models:
- MatBERT: Similar to MaterialsBERT, MatBERT is also pre-trained on a substantial collection of materials science literature. It has been successfully applied to NER tasks across various materials datasets, including those focused on perovskites and solid-state materials [54] [55].
- SciBERT: Pre-trained on a large corpus of general scientific publications from computer science and biomedicine, SciBERT serves as a strong baseline for scientific NLP tasks. It shares the same architecture as BERT but with vocabulary and pre-training data more aligned with scientific discourse [56] [18].
- BERT (Bidirectional Encoder Representations from Transformers): A general-purpose language model pre-trained on Wikipedia and BookCorpus. While powerful for general NLP tasks, it lacks specific knowledge of materials science jargon and concepts [55] [56].
The key differentiator among these models lies in their pre-training corpora. While BERT captures general language understanding, SciBERT incorporates broader scientific knowledge, and MaterialsBERT/MatBERT are specifically optimized for the materials science domain. This domain-adaptive pre-training has been consistently shown to enhance performance on downstream tasks like NER within the target domain [54] [18].
Performance Comparison on Materials Science NER Tasks
Quantitative Performance Metrics
Comprehensive evaluations across multiple studies and datasets demonstrate the advantage of domain-specific pre-training for NER in materials science. The following table summarizes key performance metrics (F1-scores) for different models across various tasks:
Table 1: NER Performance Comparison (F1-Scores) on Materials Science Datasets
| Model | Polymer Abstracts [9] | Perovskite Bandgap QA [56] | General Materials Science NER [18] | SOFC-Exp Corpus [18] |
|---|---|---|---|---|
| MaterialsBERT | ~0.90 (Polymer NER) | 54-57 | ~0.87 (Matscholar) | >0.90 |
| MatBERT | N/A | 58.6 | ~0.85 (Matscholar) [54] | N/A |
| MatSciBERT | N/A | 61.3 | N/A | N/A |
| SciBERT | ~0.85 (Polymer NER) [9] | 54-57 | ~0.82 (Matscholar) | ~0.88 |
| BERT | ~0.82 (Polymer NER) [9] | 47.5 | ~0.79 (Matscholar) | ~0.85 |
Table 2: Model Performance on Perovskite Bandgap Extraction Using Question Answering (F1-Scores) [56]
| Model | Optimal Confidence Threshold | Precision | Recall | F1-Score |
|---|---|---|---|---|
| QA MatSciBERT | 0.1 | High | High | 61.3 |
| QA MatBERT | 0.2 | High | Highest | 58.6 |
| QA MaterialsBERT | 0.05-0.2 | Medium | Medium | 54-57 |
| QA SciBERT | 0.05-0.2 | Medium | Medium | 54-57 |
| QA BERT | 0.05-0.2 | Lower | Lower | 47.5 |
| ChemDataExtractor2 | N/A | High | Lower | 45.6 |
Performance Analysis and Insights
The quantitative data reveals several important patterns:
Domain-Specific Advantage: Materials-specific models (MaterialsBERT, MatBERT, MatSciBERT) consistently outperform general-purpose models (BERT) and broader scientific models (SciBERT) on materials science NER tasks. For example, on polymer NER, MaterialsBERT achieves an F1-score of approximately 0.90, compared to ~0.85 for SciBERT and ~0.82 for BERT [9].
Task-Dependent Performance: The relative performance between domain-specific models varies based on the specific task and dataset. For instance, in perovskite bandgap extraction using Question Answering, MatSciBERT achieved the highest F1-score (61.3), closely followed by MatBERT (58.6), with MaterialsBERT and SciBERT showing similar performance (54-57) [56].
Recall vs. Precision Trade-offs: MatBERT demonstrated consistently high recall in bandgap extraction tasks, while MatSciBERT maintained high precision across different confidence thresholds [56]. This suggests potential complementarity between different domain-specific models for different application requirements.
Impact of Training Data: The superior performance of domain-adapted models highlights the importance of pre-training data composition. MaterialsBERT's training on 2.4 million materials science abstracts [9] and MatBERT's training on extensive materials science literature [54] enable better representation of domain-specific concepts and relationships.
Experimental Protocols for Materials Science NER
Standard NER Fine-Tuning Protocol
The following protocol details the standard methodology for fine-tuning and evaluating BERT-based models on materials science NER tasks, as implemented in multiple referenced studies [9] [18]:
Table 3: Key Research Reagents and Computational Tools for NER Experiments
| Resource | Type | Function/Application | Examples/Notes |
|---|---|---|---|
| Annotated Datasets | Data | Model training and evaluation | PolymerAbstracts (750 abstracts) [9], Perovskite dataset (800 abstracts) [55] |
| Pre-trained Models | Software | Base models for fine-tuning | MaterialsBERT, MatBERT, SciBERT, BERT from Hugging Face [18] |
| Annotation Tools | Software | Manual dataset creation | Prodigy annotation tool [9] |
| Computational Framework | Software | Model training infrastructure | PyTorch or TensorFlow with transformers library [18] |
| Evaluation Metrics | Methodology | Performance assessment | Precision, Recall, F1-score [55] |
Workflow Steps:
Dataset Preparation and Annotation:
- Select relevant materials science texts (abstracts or full-text paragraphs)
- Annotate entities using a predefined ontology (e.g., POLYMER, PROPERTYNAME, PROPERTYVALUE, MATERIAL)
- Implement IOBES labeling scheme for sequence tagging [55]
- Split data into training (85%), validation (5%), and test sets (10%) [9]
Model Configuration:
- Initialize with pre-trained weights from domain-specific models (MaterialsBERT, MatBERT) or baseline models (SciBERT, BERT)
- Add a linear classification layer on top of the transformer encoder with softmax activation
- Set hyperparameters: maximum sequence length = 512 tokens, dropout rate = 0.2, learning rate = 2e-5 to 5e-5 [9] [18]
Training Procedure:
- Fine-tune models on annotated NER datasets
- Use cross-entropy loss as the optimization objective
- Employ early stopping based on validation performance
- Train for approximately 3-4 epochs with batch sizes of 16 or 32 [9]
Evaluation Methodology:
- Apply trained models to held-out test sets
- Calculate precision, recall, and F1-score for each entity type
- Perform statistical significance testing where appropriate
- Conduct error analysis to identify common failure modes
Advanced Architectural Variations
For specific applications, researchers have developed enhanced architectures building upon the base models:
MatBERT-CNN-CRF for Perovskite NER [55]:
- Uses MatBERT for initial word embeddings
- Incorporates 1D Convolutional Neural Networks (CNN) to capture local contextual relationships and features
- Implements Conditional Random Field (CRF) layer for sequence decoding and label consistency
- Demonstrates improved performance compared to standard MatBERT on perovskite datasets
Question Answering for Relation Extraction [56] [57]:
- Formulates NER as a question-answering task (e.g., "What is the numerical value of bandgap of material X?")
- Fine-tunes domain-specific models on SQuAD2.0 dataset
- Enables extraction of material-property relationships across sentence boundaries
- Reduces need for task-specific retraining compared to traditional NER approaches
Diagram 1: Standard NER fine-tuning workflow for materials science texts
Application in Polymer Data Extraction
Within the context of polymer data extraction research, domain-specific models have demonstrated significant practical utility:
Large-Scale Polymer Property Extraction [1] [9]:
- MaterialsBERT successfully extracted approximately 300,000 material property records from 130,000 polymer-related abstracts
- The pipeline was scaled to process 2.4 million materials science articles, identifying 681,000 polymer-related documents
- Enabled creation of the largest automatically extracted polymer-property database, publicly available via Polymer Scholar
Hybrid NLP Pipelines [1]:
- Combined MaterialsBERT for NER with large language models (GPT-3.5, LlaMa 2) for relationship extraction
- Implemented two-stage filtering: heuristic filters followed by NER-based filters
- Extracted over one million records corresponding to 24 properties of more than 106,000 unique polymers
- Demonstrated complementary strengths of specialized NER models and generative LLMs
Diagram 2: Hybrid pipeline for polymer data extraction combining NER and LLMs
The comprehensive performance analysis presented in this Application Note demonstrates the clear advantage of domain-specific language models, particularly MaterialsBERT and MatBERT, for NER tasks in materials science. These models consistently outperform general-purpose language models and broader scientific models across various materials subdomains, including polymer science and perovskite research. The experimental protocols and architectural variations detailed herein provide practical guidance for researchers implementing these models in their data extraction pipelines. As the field evolves, the integration of specialized NER models with emerging approaches like question answering and large language models presents promising avenues for further enhancing the scale and accuracy of automated knowledge extraction from materials science literature.
Automated data extraction from scientific literature using Natural Language Processing (NLP) is critical for advancing materials discovery, particularly in polymer science. However, the specific nature and styles of scientific manuscripts present significant challenges for large-scale information extraction [1]. This document outlines a systematic approach to error analysis, categorizing common failure modes and providing detailed protocols for remediation, specifically within the context of polymer data extraction. The process involves identifying errors, classifying them using a standardized taxonomy, and implementing targeted strategies to refine both data and models, thereby improving the accuracy, explainability, and portability of NLP systems [58] [59].
Error analysis in clinical NLP has led to the development of formal taxonomies comprising numerous distinct error classes organized into multiple dimensions [58]. While specific to the clinical domain, this structured approach is directly applicable to materials science. In polymer data extraction, common failures arise from linguistic, contextual, and methodological challenges.
The table below summarizes common failure types encountered in polymer data extraction, their descriptions, and typical remediation strategies.
Table 1: Common Extraction Failures and Remedial Strategies in Polymer NLP
| Error Category | Description | Example from Polymer Literature | Primary Remedial Strategy |
|---|---|---|---|
| Contextual Understanding | Failure to resolve coreferences or interpret dependent clauses spanning multiple sentences [1]. | Missing the association between "it" in a subsequent sentence and the polymer "Poly(methyl methacrylate)" mentioned earlier. | Implement cross-sentence context models and coreference resolution [1]. |
| Non-Standard Nomenclature | Inability to recognize synonyms, acronyms, or historical terms for the same material [1]. | Treating "PMMA," "poly(methyl methacrylate)," and "acrylic glass" as distinct entities. | Curate extensive synonym dictionaries and employ models pre-trained on scientific corpora [1]. |
| Spurious Correlation | Model predictions are based on non-causal, misleading statistical patterns in the training data [59]. | Associating a specific property value with a commonly co-occurring but irrelevant word or phrase. | Use Explainable AI (XAI) techniques like SHAP and LIME to identify and mitigate biased features [59]. |
| Relationship Disambiguation | Difficulty in establishing the correct relationship between a polymer, its property, and the corresponding numerical value across complex sentences [1]. | Incorrectly linking a glass transition temperature (Tg) value to a solvent mentioned in the same sentence rather than the synthesized polymer. | Utilize dependency parsing or leverage the relational understanding of Large Language Models (LLMs) [1]. |
| Unit and Value Inconsistency | Failure to correctly extract or normalize numerical values and their units from text. | Confusing "MPa" and "GPa," or misinterpreting ranges expressed as "100-150 °C." | Develop robust pattern-matching rules and unit conversion modules. |
Experimental Protocols for Systematic Error Analysis
Protocol 1: Human-in-the-Loop (HitL) Error Analysis with Explainable AI (XAI)
This protocol uses a data-centric framework to debug NLP datasets by leveraging XAI techniques to uncover spurious correlations and bias patterns [59].
1. Materials and Software
- NLP Models: Trained classifiers (e.g., Naïve Bayes, Logistic Regression, GRU, BERT-based models) [59].
- XAI Tools: LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) libraries [59].
- Computing Environment: Standard workstation.
2. Procedure
- Step 1: Model Training and Initial Evaluation
- Train multiple classifiers on the target dataset (e.g., for entity recognition or relation classification).
- Evaluate models on a blinded test set to calculate baseline performance metrics (Precision, Recall, F1-score).
Step 2: Misclassification Identification
- Run the trained models on the test set and isolate instances with incorrect predictions (false positives and false negatives).
Step 3: XAI Interrogation
- For a representative sample of misclassified instances, generate explanations using both LIME and SHAP.
- LIME creates local, interpretable models to approximate the classifier's predictions around a specific instance.
- SHAP computes the contribution of each feature to the model's output for a given instance.
Step 4: Pattern Identification and Analysis
- Manually review the XAI explanations to identify common patterns among errors.
- Look for features that are disproportionately influencing incorrect predictions, indicating potential spurious correlations or biases (e.g., the model relying on the presence of a specific common word rather than scientifically relevant terms).
Step 5: Data Refinement and Iteration
- Based on the analysis, formulate an informed data augmentation or correction plan. This may involve:
- Adding training examples to counter spurious correlations.
- Revising annotation guidelines to address ambiguities.
- Applying targeted pre-processing to clean noisy data patterns.
- Retrain models with the refined dataset and repeat the error analysis to measure improvement.
- Based on the analysis, formulate an informed data augmentation or correction plan. This may involve:
Protocol 2: Dual-Stage Filtering for LLM-Based Data Extraction
This protocol optimizes the use of Large Language Models (LLMs) for extracting polymer-property data from full-text articles, balancing comprehensiveness with computational cost [1].
1. Materials and Software
- Corpus: A collection of full-text journal articles (e.g., ~2.4 million articles) [1].
- LLM Access: API or local access to a model such as GPT-3.5 or LlaMa 2 [1].
- NER Model: A specialized model like MaterialsBERT for initial entity recognition [1].
- Computing Environment: Server with sufficient processing power for large-scale text analysis.
2. Procedure
- Step 1: Corpus Assembly and Pre-processing
- Assemble a corpus of relevant scientific journal articles.
- Identify polymer-related documents by searching for keywords (e.g., "poly") in titles and abstracts.
- Split the full text of identified articles into individual paragraphs for processing.
Step 2: Heuristic Filtering
- Pass each paragraph through property-specific heuristic filters.
- These filters use manually curated lists of keywords and co-referents for target polymer properties (e.g., "glass transition," "Tg," "Young's modulus") to select potentially relevant paragraphs.
- Output: A subset of paragraphs (~11%) that mention target properties.
Step 3: NER Filtering
- Process the heuristic-filtered paragraphs with a NER model (e.g., MaterialsBERT) to identify named entities.
- Filter for paragraphs that contain all necessary entities for a complete data record:
Material,Property,Value, andUnit[1]. - Output: A refined subset of paragraphs (~3%) containing extractable records.
Step 4: LLM-Powered Relationship Extraction and Structuring
- Feed the final filtered paragraphs to an LLM (e.g., GPT-3.5) via a structured prompt.
- The prompt should instruct the LLM to extract the material, property, value, and unit, and output them in a structured format (e.g., JSON).
- Use few-shot learning by including 2-3 correctly parsed examples within the prompt to guide the LLM.
- Output: A structured database of polymer-property records.
Workflow Visualization
Systematic Error Analysis with XAI
Dual-Stage NLP Data Extraction
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Tools for NLP-Based Polymer Data Extraction Research
| Tool Name | Type | Primary Function | Application Note |
|---|---|---|---|
| MaterialsBERT [1] | Named Entity Recognition (NER) Model | Identifies materials science-specific named entities (e.g., polymer names, properties, values) in text. | A BERT model pre-trained on scientific literature; serves as an efficient filter before costly LLM use. |
| GPT-3.5 / LlaMa 2 [1] | Large Language Model (LLM) | Extracts and structures complex relationships from text using advanced contextual understanding. | Optimal for final extraction step; use few-shot learning for best results. Monitor API costs. |
| LIME & SHAP [59] | Explainable AI (XAI) Library | Provides post-hoc explanations for model predictions, helping to identify spurious correlations and biases. | Crucial for error analysis and building trust in model outputs. Use to debug misclassifications. |
| MedTaggerIE [58] | Rule-Based NLP Framework | Provides a framework for developing concept-specific extraction rules. | Useful for building initial, high-precision extractors for well-defined concepts, as in the NLP-CAM model. |
| BRAT / MedTator [58] | Annotation Tool | Facilitates the manual annotation of text corpora to create gold-standard training and test data. | Essential for error analysis and model refinement, supporting collaborative annotation efforts. |
Comparative Assessment of Polymer Informatics Pipelines (PIKS, ChemDataExtractor)
1. Introduction
The ever-growing volume of polymer science literature presents a significant challenge for researchers, making manual data extraction a bottleneck for informatics and materials discovery. Automated data extraction pipelines are crucial for constructing the large-scale, structured databases required for machine learning and predictive modeling. This application note provides a comparative assessment of two distinct approaches to polymer informatics: the PIpeline for Knowledge extraction in Polymer Science (PIKS), representing modern workflows utilizing large language models (LLMs) and specialized language models, and ChemDataExtractor, a established, chemistry-aware natural language processing (NLP) tool. The assessment is framed within the broader context of advancing natural language processing for polymer data extraction research, highlighting the evolution from rule-based systems to generative AI.
2. System Overviews and Comparative Analysis
2.1 Core Architectures and Methodologies
- ChemDataExtractor: This is a Python toolkit that uses a combination of rule-based systems and supervised machine learning for named entity recognition (NER) to identify chemical entities and property values in scientific text. It primarily processes text from HTML or XML but uses a plug-in, PDFDataExtractor, to handle the complex, latent metadata of PDF files. PDFDataExtractor employs a template-based approach to reconstruct the logical structure of a scientific article (e.g., title, authors, abstract, body text) and extract metadata, which is then fed into ChemDataExtractor's chemical information extraction pipeline [60].
- PIKS (Representative LLM-driven Pipeline): While a specific "PIKS" system is not detailed in the search results, several recent studies describe modern pipelines that represent its core principles. These pipelines leverage large language models (LLMs) like GPT-3.5, GPT-4, or LlaMa 2, and/or specialized BERT-style models (e.g., MaterialsBERT, polyBERT) for end-to-end data extraction [9] [1] [61]. These models are applied through advanced prompt engineering (e.g., the ChatExtract method) or fine-tuning to directly identify material-property-value triplets from full-text articles, often incorporating multi-stage filtering to improve efficiency and accuracy [1] [62].
Table 1: High-Level Architectural Comparison
| Feature | ChemDataExtractor | PIKS (Representative LLM-driven Pipeline) |
|---|---|---|
| Core Approach | Rule-based & classical ML for NER, requires PDF preprocessing [60] | Transformer-based models (LLMs or specialized BERT) for generative or classificatory extraction [9] [1] [62] |
| Primary Input | Best with semantically tagged HTML/XML; PDFs require a separate plug-in [60] | Can process plain text from PDFs directly; some systems can handle full PDF content [1] [63] |
| Key Strength | High precision through domain-specific rules and templates; well-established for specific property types [60] | High adaptability and accuracy on complex, multi-value sentences; requires minimal upfront rule creation [62] |
| Typical Output | Structured data (e.g., JSON) with document metadata and chemical entities [60] | Structured data (e.g., Material-Property-Value triplets) ready for database ingestion [9] [1] |
2.2 Performance and Application Data
A direct, quantitative comparison between a specific "PIKS" and ChemDataExtractor is not available in the provided literature. However, performance metrics for their respective classes of technology are reported.
Table 2: Reported Performance Metrics of Pipeline Technologies
| Technology / Pipeline | Reported Performance | Context / Property Extracted |
|---|---|---|
| PDFDataExtractor (ChemDataExtractor plug-in) | Achieved promising precision for all key assessed metadata areas [60] | Evaluation on a self-created article set for document metadata extraction. |
| MaterialsBERT-based Pipeline | Extracted ~300,000 property records from ~130,000 abstracts in 60 hours [9] | General-purpose property extraction from polymer literature abstracts. |
| GPT-4 with ChatExtract | ~91% precision, ~84% recall [62] | Critical cooling rates for metallic glasses (complex, multi-value data). |
| LLaMa 2-7B with Fine-Tuning | 91.1% accuracy, 98.7% F1-score [3] | Extraction of polymer injection molding parameters (224 fine-tuning samples). |
| GPT-4 in End-to-End Workflow | Accuracy comparable to manually curated datasets [63] | Extraction of organic photovoltaic materials and their properties. |
3. Experimental Protocols
3.1 Protocol for Polymer Data Extraction using a ChemDataExtractor-based Pipeline
- PDF Preprocessing and Structure Reconstruction:
- Input a scientific article in PDF format into the PDFDataExtractor tool [60].
- The tool uses PDFMiner to perform layout analysis, converting the PDF into a sequence of text blocks with positional information.
- A template-based system is applied to classify text blocks into logical units (title, authors, abstract, sections, etc.) and reconstruct the article's semantic structure.
- Metadata and Text Extraction:
- PDFDataExtractor extracts and outputs key metadata (title, authors, journal, DOI, etc.) and the structured body text in JSON or plain text format.
- Chemical Information Extraction:
- The structured output is passed to the core ChemDataExtractor engine.
- The engine applies its chemistry-aware NER model to identify polymer names, properties, and values within the text.
- Rule-based parsers and relationship extraction algorithms are used to associate property values with their corresponding materials.
- Output:
- The final output is a structured data record containing the document metadata and the extracted chemical data, which can be appended to a database.
3.2 Protocol for Polymer Data Extraction using a PIKS-style LLM-driven Pipeline
- Corpus Assembly and Pre-filtering:
- Assemble a corpus of full-text journal articles (e.g., 2.4 million papers) [1].
- Identify polymer-relevant documents using keyword searches (e.g., "poly") in titles and abstracts.
- Text Segmentation and Filtering:
- Divide the full text of relevant articles into individual paragraphs.
- Apply a two-stage filtering process to identify paragraphs containing extractable data [1]:
- Heuristic Filter: Use property-specific keywords to find paragraphs mentioning a target property.
- NER Filter: Use a model like MaterialsBERT to confirm the presence of all necessary named entities (material, property, value, unit) in the paragraph.
- Data Extraction with LLMs/Specialized Models:
- Option A (Prompt-based with Conversational LLM): Use the ChatExtract method [62].
- Feed filtered text passages (e.g., title, preceding sentence, target sentence) to a conversational LLM like GPT-4.
- Apply a series of engineered prompts: first to classify sentence relevance, then to extract data for single- or multi-value sentences.
- Use follow-up, uncertainty-inducing questions to verify extracted data and minimize hallucinations.
- Option B (Fine-tuned Open-Source LLM): For a specific domain (e.g., processing parameters), fine-tune an open-source model like LLaMa-2-7B using a QLoRA framework on a small set of annotated samples (e.g., 224 samples) [3].
- Option A (Prompt-based with Conversational LLM): Use the ChatExtract method [62].
- Output:
- The LLM outputs structured data, such as JSON objects containing the material name, property name, numerical value, and unit.
Polymer Informatics Pipeline Architecture Comparison
4. The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Software and Models for Polymer Data Extraction
| Tool / Model | Type | Primary Function in Pipeline |
|---|---|---|
| PDFMiner | Software Library | PDF layout analysis; converts PDFs into a sequence of text blocks for initial processing [60]. |
| ChemDataExtractor | NLP Toolkit | Chemistry-aware named entity recognition and relationship extraction from scientific text [60] [63]. |
| PDFDataExtractor | Software Plug-in | Reconstructs the logical structure of and extracts metadata from scientific PDFs for ChemDataExtractor [60]. |
| MaterialsBERT | Specialized Language Model | A BERT model pre-trained on materials science text; serves as an encoder for NER tasks in polymer property extraction [9] [1]. |
| polyBERT | Specialized Language Model | A Transformer model trained on polymer SMILES strings; generates numerical fingerprints for polymer structures to enable property prediction [61]. |
| GPT-4 / ChatGPT | Large Language Model (LLM) | Used in conversational data extraction workflows (e.g., ChatExtract) for high-accuracy, zero-shot or few-shot data extraction from text [62]. |
| LlaMa 2 | Large Language Model (LLM) | An open-source LLM that can be fine-tuned for specific information extraction tasks in polymer science [1] [3]. |
| GROBID | Software Library | Extracts and parses raw text from PDFs, particularly focusing on bibliographic data and document structure segmentation [64]. |
The field of polymer informatics suffers from a critical data scarcity, with a substantial amount of valuable historical data trapped in unstructured text within millions of published scientific articles [1] [9]. Natural language processing (NLP) techniques, particularly those leveraging large language models (LLMs), have emerged as a powerful solution to this challenge, enabling the automated, large-scale extraction of structured polymer-property data from literature [1] [3]. This automated data extraction is a critical prerequisite for advancing materials discovery, as it provides the high-quality, structured datasets necessary to train robust predictive machine learning (ML) models [9] [65]. These models can then map polymer structures to target properties within a Quantitative Structure-Property Relationship (QSPR) framework, allowing for the rapid computational screening of promising candidates prior to laboratory synthesis [66]. This application note details the protocols for constructing an NLP-driven data extraction pipeline and for leveraging the resulting data to build and validate predictive models for polymer properties, thereby quantifying the impact of literature mining on model performance.
Experimental Protocols
Protocol 1: NLP-Driven Polymer Data Extraction Pipeline
This protocol describes the methodology for automatically extracting polymer-property records from a large corpus of scientific literature, based on established frameworks [1] [9] [3].
2.1.1 Reagents and Materials
- Corpus of Journal Articles: A collection of 2.4 million full-text materials science articles from publishers like Elsevier, Wiley, Springer Nature, American Chemical Society, and the Royal Society of Chemistry [1].
- Computational Resources:
- LLM API/Services: Access to commercial LLMs such as GPT-3.5 or open-source models like LlaMa 2 (e.g., the 7B parameter version for chat) [1] [3].
- NER Model: A pre-trained domain-specific model such as MaterialsBERT, which is derived from PubMedBERT and fine-tuned on materials science text [1] [9].
- Software Libraries: Python environment with libraries for NLP (e.g., Transformers, SpaCy) and data manipulation (e.g., Pandas, NumPy).
2.1.2 Procedure
- Corpus Assembly and Polymer Identification: Begin with a pre-assembled corpus of journal articles. Identify polymer-related documents by searching for the term 'poly' in the titles and abstracts. This typically filters the corpus down to hundreds of thousands of relevant articles (e.g., ~681,000 from a 2.4 million article corpus) [1].
- Text Unit Segmentation: Process each full-text article, treating individual paragraphs as the fundamental text units for data extraction. This can result in tens of millions of paragraphs (e.g., 23.3 million from 681,000 articles) [1].
- Two-Stage Paragraph Filtering:
- Heuristic Filtering: Pass each paragraph through property-specific heuristic filters. These filters use manually curated lists of keywords and co-referents (e.g., "T_g", "glass transition temperature") for target properties (e.g., thermal, mechanical, optical) to identify paragraphs likely to contain relevant data. This typically retains a significant portion of paragraphs (e.g., ~11%) [1].
- NER Filtering: Apply a named entity recognition (NER) filter to the heuristic-filtered paragraphs. Use a model like MaterialsBERT to verify the presence of all necessary named entities:
material,property,value, andunit. This step confirms the existence of a complete, extractable record and further refines the dataset (e.g., to ~3% of original paragraphs) [1].
- Information Extraction with LLMs:
- Prompt Engineering: For each paragraph that passes the NER filter, engineer a specific prompt instructing the LLM (e.g., GPT-3.5 or LlaMa 2) to extract the material name, property name, numerical value, and unit. Use few-shot learning by including several curated examples within the prompt to guide the model's output format and accuracy [1] [3].
- Structured Output Parsing: Call the LLM API with the engineered prompts. Parse the model's responses to structure the extracted information into a standardized format, such as a JSON record or a database row [3].
- Data Consolidation and Validation: Aggregate all extracted records into a structured database (e.g., SQL, Pandas DataFrame). Implement a validation step, which may involve range checks for numerical values, unit normalization, and, if resources allow, manual spot-checking of a subset of records against the original text to estimate error rates [1].
2.1.3 Expected Outcomes The execution of this pipeline results in a large-scale, structured dataset of polymer-property pairs. For example, the described pipeline successfully extracted over one million records corresponding to 24 different properties for over 106,000 unique polymers from a corpus of ~681,000 polymer-related articles [1].
Protocol 2: Developing Predictive Models from Extracted Data
This protocol outlines the process of using the extracted polymer-property data to train and validate machine learning models for property prediction [66] [65].
2.2.1 Reagents and Materials
- Extracted Polymer-Property Dataset: The structured dataset generated from Protocol 1.
- Polymer Structure Representation: Simplified Molecular Input Line Entry System (SMILES) strings or other structural representations (e.g., Ring Repeating Units - RRU) for the polymers in the dataset [66] [65].
- Computational Resources:
- Machine Learning Libraries: Scikit-learn, XGBoost, PyTorch, or TensorFlow.
- Cheminformatics Toolkit: RDKit for converting SMILES strings into numerical descriptors or feature vectors [65].
2.2.2 Procedure
- Dataset Preparation and Featurization:
- Data Cleaning: Handle missing values and outliers. For properties with multiple reported values, use a consistent aggregation method, such as taking the median [65].
- Structure Featurization: Convert the polymer's structural representation (e.g., SMILES) into a numerical feature vector. This can be achieved using RDKit to generate a set of molecular descriptors or by creating a binary feature vector from the SMILES string itself (e.g., a 1024-bit binary vector) [65].
- Train-Test Split: Split the featurized dataset into a training set (e.g., 80%) and a hold-out test set (e.g., 20%) to evaluate the model's performance on unseen data [65].
- Model Training and Validation:
- Model Selection: Train a diverse set of regression models. A recommended suite includes:
- Random Forest Regressor
- XGBoost Regressor
- Gradient Boosting Regressor
- Support Vector Regressor (SVR)
- Linear Regression [65]
- Hyperparameter Tuning: Use techniques like grid search or random search with cross-validation on the training set to optimize the hyperparameters for each model.
- Model Validation: Perform rigorous validation using the hold-out test set. Employ k-fold cross-validation (e.g., 5-fold or 10-fold) on the training data to assess model stability and avoid overfitting [66].
- Model Selection: Train a diverse set of regression models. A recommended suite includes:
- Model Evaluation and Interpretation:
- Performance Metrics: Calculate a standard set of metrics on the test set to quantify performance. Key metrics include:
- Coefficient of Determination (R²)
- Root Mean Squared Error (RMSE)
- Mean Absolute Error (MAE) [65]
- Model Interpretation: Use explainable AI techniques like SHapley Additive exPlanations (SHAP) to interpret the model's predictions and identify the most important features (descriptors) influencing the target property [66].
- Performance Metrics: Calculate a standard set of metrics on the test set to quantify performance. Key metrics include:
2.2.3 Expected Outcomes A validated predictive model capable of accurately estimating a target polymer property from its structure. For instance, a Random Forest model trained on such data has been shown to achieve high R² scores, such as 0.88 for melting temperature prediction [65].
Results and Data Presentation
Performance of Data Extraction Pipelines
The table below summarizes the quantitative performance and cost-effectiveness of different models used for polymer data extraction, as evaluated in a large-scale study [1].
Table 1: Performance and Cost Analysis of Data Extraction Models
| Model | Model Type | Extraction Scale (Example) | Key Strengths | Cost Considerations |
|---|---|---|---|---|
| MaterialsBERT | Named Entity Recognition (NER) | ~300,000 records from ~130,000 abstracts [9] | Superior performance on materials science-specific entities; no per-inference monetary cost [1] [9] | Lower computational cost for inference compared to LLMs; requires domain-specific pre-training [1] |
| GPT-3.5 | Large Language Model (LLM) | Over 1 million records from ~681,000 full-text articles [1] | High versatility; eliminates need for extensive labeled data via few-shot learning [1] | Significant monetary cost due to API calls; high energy consumption [1] |
| LlaMa 2 | Large Language Model (LLM) | Effective for targeted extraction (e.g., processing parameters) [3] | Open-source; can be fine-tuned for specific domains (e.g., with QLoRA) [3] | High computational cost for self-hosting; requires technical expertise for fine-tuning and deployment [1] |
Performance of Predictive Machine Learning Models
The following table compares the performance of various ML algorithms in predicting key polymer properties using data extracted from literature, demonstrating the utility of the mined data [65].
Table 2: Predictive Performance of Machine Learning Models for Polymer Properties
| Polymer Property | Best Performing Model | Coefficient of Determination (R²) | Alternative Models Tested |
|---|---|---|---|
| Glass Transition Temperature (T_g) | Random Forest | 0.71 [65] | XGBoost, Gradient Boosting, SVR, Linear Regression [65] |
| Thermal Decomposition Temperature (T_d) | Random Forest | 0.73 [65] | XGBoost, Gradient Boosting, SVR, Linear Regression [65] |
| Melting Temperature (T_m) | Random Forest | 0.88 [65] | XGBoost, Gradient Boosting, SVR, Linear Regression [65] |
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Tools
| Item | Function/Description | Application Note |
|---|---|---|
| MaterialsBERT | A domain-specific language model pre-trained on 2.4 million materials science abstracts for superior named entity recognition (NER) [9]. | Powers the initial NER filtering and can be used as a standalone extractor for well-defined entities in abstracts and full texts [1] [9]. |
| GPT-3.5 / LlaMa 2 | Large Language Models (LLMs) used for parsing complex textual relationships and extracting structured data from full-text paragraphs via prompt engineering [1] [3]. | Ideal for few-shot learning where labeled data is scarce. LlaMa 2 is open-source and can be fine-tuned for specific tasks like processing parameter extraction [3]. |
| RDKit | An open-source cheminformatics software toolkit used to compute molecular descriptors and convert SMILES strings into numerical feature vectors [65]. | Critical for the featurization step in predictive modeling, transforming polymer structures into a format usable by machine learning algorithms [65]. |
| Random Forest / XGBoost | Ensemble tree-based machine learning algorithms known for high predictive accuracy and robustness in handling tabular data [65]. | Often top performers in QSPR modeling for polymer properties like thermal transition temperatures [66] [65]. |
| SHAP (SHapley Additive exPlanations) | A game theory-based method to interpret the output of any machine learning model, explaining the contribution of each feature to a prediction [66]. | Used post-modeling to provide insights into which structural features most influence a polymer's properties, adding interpretability to the "black box" model [66]. |
Workflow and Signaling Diagrams
Data Extraction to Prediction Pipeline
Predictive Model Development Workflow
The glass transition temperature (Tg) is a critical property of amorphous polymers, marking their transition from a rigid, glassy state to a softer, rubbery state. This property determines the operational temperature range and application suitability of polymer materials, from hard plastics to rubber elastomers [67]. The accurate prediction of Tg is therefore paramount for the rational design of new polymeric materials.
Traditional experimental methods for determining Tg, such as Differential Scanning Calorimetry (DSC) and Dynamic Mechanical Analysis (DMA),, while accurate, can be time-consuming, costly, and susceptible to experimental variations [68]. The field of polymer informatics seeks to overcome these limitations by leveraging computational power and data science.
This case study explores the integration of two powerful computational paradigms: the application of Natural Language Processing (NLP) for large-scale extraction of polymer data from scientific literature, and the use of Molecular Dynamics (MD) simulations and Machine Learning (ML) models for the rapid and accurate prediction of Tg. We detail the protocols for extracting and validating Tg data, providing a framework for reliable, data-driven polymer design.
Workflow for Data Extraction and Validation
The process of validating Tg predictions begins with the large-scale acquisition of reliable data, followed by the application of computational models. The diagram below illustrates the integrated workflow.
Data Extraction Methodology Using NLP
The first stage involves building a structured polymer property database from unstructured scientific text. This process, as detailed by the pipeline that processed ~2.4 million articles, involves several key steps [1].
Text Preprocessing and Filtering
A vast corpus of scientific literature is assembled. To focus on polymer-relevant documents, a keyword filter (e.g., "poly" in titles and abstracts) is applied, identifying ~681,000 articles. The full text of these articles is split into individual paragraphs, creating millions of text units for processing [1].
Dual-Stage Filtering for Relevance
Two sequential filters identify paragraphs containing extractable property data:
- Heuristic Filter: Paragraphs are scanned for mentions of target properties (e.g., "glass transition temperature," "Tg") and their co-referents. This step reduces the dataset to the most relevant paragraphs (~11% in the cited study) [1].
- Named Entity Recognition (NER) Filter: A model like MaterialsBERT is used to identify specific named entities within the text: the material name, the property name, the numerical value, and its unit [1]. A paragraph must contain all these entities to confirm a complete, extractable data record. This step further refines the dataset (~3% of original paragraphs) [1].
Information Extraction and Structuring
The filtered paragraphs are processed to establish relationships between the recognized entities. This can be achieved using two primary methods:
- LLM-based Extraction: Large Language Models (LLMs) like GPT-3.5 or specialized models like polyBERT can be prompted to output structured data (e.g., JSON) containing the polymer name, property, value, and unit [1] [69].
- Rule-based Extraction: Pre-defined rules can link entities based on syntactic dependencies within the sentence.
The final output is a structured database, such as Polymer Scholar, which houses the extracted polymer-property data for public use [1].
Protocols for Tg Prediction and Validation
Once a dataset of experimental Tg values is established, computational models can be developed and validated against it.
Machine Learning Prediction Protocol
Machine learning offers a high-throughput method for Tg prediction. The following protocol is adapted from recent research [68].
Table 1: Key Steps for ML-Based Tg Prediction
| Step | Description | Key Parameters & Notes |
|---|---|---|
| 1. Data Collection | Collect polymer SMILES strings and corresponding Tg values from databases (e.g., PolyInfo). | Focus on homopolymers for model simplicity. Dataset size: >1000 data points. |
| 2. Data Preparation | Convert SMILES strings into numerical descriptors. | One Hot Encoding (OHE): Generates binary fingerprints via RDKit. Faster and performed well in studies [68]. Natural Language Processing (NLP): Uses character embedding; required for RNN models [68]. |
| 3. Model Training | Train ML models on the prepared dataset. | Recommended Models: XGBoost (high stability, R² ~0.77) or ANN (highest R² ~0.79) [68]. Critical Parameter: SMILES character length should be optimized; >200 characters can cause performance degradation [68]. |
| 4. Validation | Validate model predictions against a hold-out test set or new experimental data. | The XGBoost model demonstrated an average deviation of ~9.76°C from actual Tg values [68]. |
Specialized chemical language models like polyBERT represent a significant advancement. This model, trained on 80 million polymer structures, treats chemical structures as a language, using transformer architecture to understand atomic-level "grammar and syntax." It performs fingerprinting and property prediction orders of magnitude faster than traditional methods, enabling the screening of vast chemical spaces [69].
Ensemble Molecular Dynamics Simulation Protocol
Molecular Dynamics provides a physics-based approach to Tg prediction. The protocol below emphasizes an ensemble method to ensure reliability and quantify uncertainty [67].
Table 2: Protocol for Ensemble MD Simulation of Tg
| Step | Description | Key Parameters & Notes |
|---|---|---|
| 1. System Construction | Build an atomistic model of the cross-linked polymer system. | Use a builder tool (e.g., MedeA thermoset builder). Define a cross-linking ratio (e.g., 95%) [67]. |
| 2. Ensemble Setup | Create multiple (N) replicas of the same system. | Each replica is initialized with a different random seed to sample chaotic dynamics. N ≥ 10 is required for 95% confidence intervals <20 K [67]. |
| 3. Simulation Execution | Run concurrent MD simulations at a range of temperatures. | Method: Use a "concurrent" scenario where all temperatures are simulated in parallel, reducing wall-clock time from days to hours [67]. Simulation Time: Optimal protocol is 4 ns of burn-in followed by 2 ns of production run time [67]. |
| 4. Data Analysis | Calculate density for each replica and temperature. Plot density vs. temperature. | The Tg is identified as the intersection point of the linear fits from the glassy and rubbery regions. The variation across the ensemble provides the aleatoric uncertainty [67]. |
Essential Research Reagents and Materials
The following table lists key materials and computational tools used in the experiments cited in this study.
Table 3: Research Reagent Solutions for Tg Studies
| Name | Type | Function/Description |
|---|---|---|
| Diglycidyl Ether of Bisphenol A (DGEBA) | Epoxy Resin | A common epoxy resin monomer used in thermosets, cured with amines to form high-Tg networks [67]. |
| 4,4'-Diaminodiphenyl Sulphone (44DDS) | Aromatic Amine Curative | A curing agent for epoxy resins; contributes to high stiffness and high Tg in the resulting polymer [67]. |
| Methacrylamide (MAAm) | Monomer | Used in RAFT polymerization to create polymers with Upper Critical Solution Temperature (UCST) behavior [70]. |
| CTCA | RAFT Agent | A chain transfer agent used to control the radical polymerization of MAAm, enabling precise molecular weight control [70]. |
| ACVA | Initiator | A thermal initiator (Azobis(4-cyanovaleric acid)) used to start the RAFT polymerization reaction [70]. |
| polyBERT | AI Model | A chemical language model that learns from polymer structures for ultrafast fingerprinting and property prediction [69]. |
| MaterialsBERT | AI Model | A named entity recognition model fine-tuned on materials science text to identify materials, properties, and values in literature [1]. |
Results and Comparative Analysis
The integration of data extraction and computational prediction yields a powerful pipeline for polymer informatics. The table below summarizes the performance of the different Tg prediction methods discussed.
Table 4: Comparison of Tg Prediction Methodologies
| Method | Key Principle | Reported Performance / Uncertainty | Advantages | Disadvantages |
|---|---|---|---|---|
| Experimental (DMA) | Physical measurement of mechanical response to temperature. | Variation of 20-30 K due to cross-linking degree and technique [67]. | Gold standard for validation. | Time-consuming, resource-intensive. |
| Ensemble MD | Physics-based simulation of density-temperature relationship. | Confidence intervals <20 K achievable with ≥10 replicas [67]. | Provides atomic-level insight; quantifies uncertainty. | Computationally expensive; force-field dependent. |
| XGBoost (SMILES) | Machine learning using molecular fingerprints. | R² of 0.774; avg. deviation ~9.76°C [68]. | Very fast prediction; high-throughput screening. | Requires large dataset; limited interpretability. |
| polyBERT | Chemical language model using transformer architecture. | >100x faster than fingerprinting; predicts 29 properties [69]. | Ultrafast; understands chemical "language"; multi-task. | Complex model training; requires significant data. |
The relationship between the number of MD replicas and the prediction uncertainty is a key finding. The uncertainty, expressed as the confidence interval, scales as N⁻⁰·⁵. This statistical principle provides a clear guide for researchers: running an ensemble of at least 10 replicas is necessary to achieve a reliable prediction with a 95% confidence interval below 20 K [67]. This rigorous approach to uncertainty quantification (UQ) is critical for making MD predictions reproducible and actionable for experimentalists [67].
Conclusion
The integration of NLP technologies for polymer data extraction represents a paradigm shift in materials research, effectively addressing the critical challenge of data scarcity that has long hampered innovation. The development of specialized tools like MaterialsBERT and automated pipelines demonstrates the feasibility of efficiently transforming unstructured scientific text into structured, machine-readable knowledge—with one system extracting approximately 300,000 property records from 130,000 abstracts in just 60 hours. For biomedical and clinical researchers, these advances offer unprecedented opportunities to accelerate polymer-based drug delivery system development, biomaterial design, and medical device innovation by rapidly uncovering complex chemistry-structure-property relationships. Future directions should focus on enhancing multilingual NLP capabilities, developing more sophisticated normalization techniques for complex polymer nomenclature, improving model interpretability for scientific discovery, and creating specialized extraction systems for biomedical polymer applications. As the NLP market continues its robust growth—projected to maintain a 10.9% CAGR from 2025-2033—the polymer science community stands to benefit tremendously from these technological advancements, ultimately accelerating the translation of polymeric materials from laboratory research to clinical applications that improve human health and treatment outcomes.
References
- 1. Data extraction from polymer literature using large ... [https://www.nature.com/articles/s43246-024-00708-9]
- 2. Automated Extraction of Material Properties using LLM ... [https://arxiv.org/html/2510.01235v1]
- 3. Intelligent information extraction pipeline driven by large ... [https://www.sciencedirect.com/science/article/abs/pii/S0032386125008614]
- 4. Contrast Checker [https://webaim.org/resources/contrastchecker/]
- 5. Opportunities and challenges of text mining in materials ... [https://www.sciencedirect.com/science/article/pii/S2589004221001231]
- 6. Natural Language Processing in 2025: Trends & Use Cases [https://www.aezion.com/blogs/natural-language-processing/]
- 7. Natural Language Processing vs. Text Mining: The Difference [https://www.coherentsolutions.com/insights/natural-language-processing-vs-text-mining-key-differences]
- 8. Applications of natural language processing and large ... [https://www.nature.com/articles/s41524-025-01554-0]
- 9. A general-purpose material property data extraction ... [https://www.nature.com/articles/s41524-023-01003-w]
- 10. Natural Language Processing as Pathway to Polymer ... [https://brinsonlab.pratt.duke.edu/research/mgp/NLP-curation]
- 11. Top 10 NLP tools in 2025: a complete guide for developers ... [https://kairntech.com/blog/articles/top-10-nlp-tools-in-2025-a-complete-guide-for-developers-and-innovators/]
- 12. Polymer Informatics: Current and Future Developments [https://www.azom.com/article.aspx?ArticleID=20730]
- 13. Periodicity-aware deep learning for polymers [https://www.nature.com/articles/s43588-025-00903-9]
- 14. [2505.13494] Polymer Data Challenges in the AI Era [https://arxiv.org/abs/2505.13494]
- 15. Large Language Model Versus Manual Review for Clinical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12599480/]
- 16. Data Extraction Tool May Lead to Discovery of New Polymers [https://research.gatech.edu/data-extraction-tool-may-lead-discovery-new-polymers]
- 17. Unified multimodal multidomain polymer representation for ... [https://www.nature.com/articles/s41524-025-01652-z]
- 18. MatSciBERT: A materials domain language model for text ... [https://www.nature.com/articles/s41524-022-00784-w]
- 19. Data Extraction Tool May Lead to Discovery of New Polymers [https://research.gatech.edu/data-extraction-tool-may-lead-discovery-new-polymers-0]
- 20. A general-purpose material property data extraction ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10073792/]
- 21. PolyNERE: A Novel Ontology and Corpus for Named Entity ... [https://aclanthology.org/2024.lrec-main.1126/]
- 22. From text to insight: large language models for chemical data ... [https://pubs.rsc.org/en/content/articlehtml/2025/cs/d4cs00913d]
- 23. Advances in Fuel Cells Technologies and Applications ... [https://www.nexanteca.com/reports/%E2%80%8Badvances-fuel-cells-technologies-and-applications-2025-program]
- 24. Tasks & Focus Areas [https://ieafuelcell.com/tasks/]
- 25. 7 New Solar Panel Technology Trends for 2025 [https://www.greenlancer.com/post/solar-panel-technology-trends]
- 26. Recent Advances in Solar Cell Technology for ... [https://www.altenergymag.com/article/2025/09/recent-advances-in-solar-cell-technology-for-transportation-applications-/46071]
- 27. Key trends and technologies in drug delivery for 2025 and ... [https://www.linkedin.com/pulse/key-trends-technologies-drug-delivery-2025-mwt7e]
- 28. Bridging the Gap: The Role of Advanced Formulation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12579833/]
- 29. PolymerScholar 2.0 [https://polymerscholar.org/]
- 30. Instruction Guide [https://polymerscholar.org/guide]
- 31. OpenPoly: A Polymer Database Empowering ... [https://link.springer.com/article/10.1007/s10118-025-3402-y]
- 32. Named Entity Recognition: A Practical 2025 Guide [https://labelyourdata.com/articles/data-annotation/named-entity-recognition]
- 33. A review of named entity recognition: from learning ... [https://link.springer.com/article/10.1007/s10462-025-11321-8]
- 34. Few-shot biomedical NER empowered by LLMs-assisted data ... [https://biodatamining.biomedcentral.com/articles/10.1186/s13040-025-00443-y]
- 35. A Paraphrase-Augmented Framework for Low-Resource ... [https://arxiv.org/html/2510.17720v1]
- 36. Resource-efficient instruction tuning of large language ... [https://www.sciencedirect.com/science/article/abs/pii/S153204642500125X]
- 37. Enhancing NER Performance in Low-Resource Pakistani ... [https://aclanthology.org/2025.wnut-1.13/]
- 38. Custom NER evaluation metrics - Foundry Tools [https://learn.microsoft.com/en-us/azure/ai-services/language-service/custom-named-entity-recognition/concepts/evaluation-metrics]
- 39. A Review of Multiscale Computational Methods in Polymeric ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6432151/]
- 40. ChemProps: A RESTful API enabled database for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7955638/]
- 41. IUPAC polymer nomenclature [https://en.wikipedia.org/wiki/IUPAC_polymer_nomenclature]
- 42. Polymer nomenclature | Polymer Chemistry Class Notes [https://fiveable.me/polymer-chemistry/unit-1/polymer-nomenclature/study-guide/pyKt5pnXYmU846yI]
- 43. Interpretability research of deep learning: A literature survey [https://www.sciencedirect.com/science/article/abs/pii/S1566253524004998]
- 44. An Explainable Method for Automatic Extraction of Natural ... [https://www.mdpi.com/2076-3417/15/22/11854]
- 45. This Reads Like That: Deep Learning for Interpretable ... [https://arxiv.org/abs/2310.17010]
- 46. Text has enhanced contrast | ACT Rule | WAI [https://www.w3.org/WAI/standards-guidelines/act/rules/09o5cg/]
- 47. Color Contrast Guidelines for Text & UI Accessibility [https://daily.dev/blog/color-contrast-guidelines-for-text-and-ui-accessibility]
- 48. Research on a multivariate measurement system for ... [https://www.nature.com/articles/s41598-025-23236-z]
- 49. Recent Progress of Artificial Intelligence Application in ... [https://www.mdpi.com/2073-4360/17/12/1667]
- 50. Automated knowledge extraction from polymer literature ... [https://pubmed.ncbi.nlm.nih.gov/33458607/]
- 51. from Data literature using large language models extraction polymer [https://www.nature.com/articles/s43246-024-00708-9?error=cookies_not_supported&code=d7d81561-11a4-4633-898a-a33eb9c45ed9]
- 52. How to choose colors for data visualizations [https://www.atlassian.com/data/charts/how-to-choose-colors-data-visualization]
- 53. Experimental Design in Polymer Chemistry—A Guide towards ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8468855/]
- 54. Quantifying the advantage of domain-specific pre-training ... [https://www.sciencedirect.com/science/article/pii/S2666389922000733]
- 55. Named entity recognition in the perovskite field based on ... [https://www.sciencedirect.com/science/article/abs/pii/S0927025624002350]
- 56. Question Answering models for information extraction from ... [https://www.nature.com/articles/s43246-025-00979-w]
- 57. Question Answering models for information extraction from ... [https://arxiv.org/html/2405.15290v2]
- 58. A taxonomy for advancing systematic error analysis in multi ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11187420/]
- 59. A data centric HitL framework for conducting a systematic ... [https://www.nature.com/articles/s41598-025-13452-y]
- 60. PDFDataExtractor: A Tool for Reading Scientific Text and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9049592/]
- 61. polyBERT: a chemical language model to enable fully ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10336012/]
- 62. Extracting accurate materials data from research papers ... [https://www.nature.com/articles/s41467-024-45914-8]
- 63. AI-Powered Workflow for Constructing Organic Materials ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12572996/]
- 64. Collage: Decomposable Rapid Prototyping for Co- ... [https://arxiv.org/html/2410.23478v2]
- 65. Estimation and Prediction of the Polymers' Physical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10780762/]
- 66. Quantitative structure-property relationship (QSPR) ... [https://www.sciencedirect.com/science/article/abs/pii/S1385894723014997]
- 67. Rapid, Accurate and Reproducible Prediction of the Glass Transition Temperature Using Ensemble-Based Molecular Dynamics Simulation - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC11823416/]
- 68. Prediction of Glass Transition Temperature of Polymers Using Simple Machine Learning - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC11398084/]
- 69. Revolutionary AI Algorithm Learns Chemical Language and ... [https://research.gatech.edu/revolutionary-ai-algorithm-learns-chemical-language-and-accelerates-polymer-research]
- 70. Experimental Design in Polymer Chemistry—A Guide ... [https://www.mdpi.com/2073-4360/13/18/3147]